

Hay veces que conoces a personas dentro de tu profesión que son maestros dentro de una determinada disciplina. Eso es lo que me pasó a mi cuando comencé a hablar con Javier Marcilla de NinjaSEO hará unos pocos meses atrás. Era un crack en muchos temas de los que todavía no había demasiada información y además me cayó especialmente bien porque era sumamente comunicativo (una virtud muy poco común entre los SEOs).

Cuando vi el post que me mandó para publicar pensé… «este tío está loco…» así que lo tenía que traer a Blogger3cero 🙂
Javier es un verdadero crack del SEO. No dudé en pedirle cierto consejo para montar mi PBN y los resultados por su parte fueron extraordinarios. Pero quiero que lo compruebes directamente tú… Hoy viene a enseñarnos todo acerca de Scrapebox. Una de las herramientas SEO más controvertidas de nuestra profesión.
###

¡Hola, soy Javier de NinjaSEO, bienvenido/a a esta Mega Guía de Scrapebox en Español!
La idea de crear este recurso surgió de una conversación con Dean, porque no es que Scrapebox sea un desconocido, pero en general sigue siendo una herramienta poco utilizada y conocida fuera de los círculos BlackHat.
Así que… NinjaSEO al rescate 😉
Y muchas gracias Dean por ofrecerme amablemente tu blog para dar a conocer un poco más a esta máquina del SEO que es Scrapebox.
En este artículo aprenderás como usarlo para algunas tareas SEO WhiteHat, y también para hacer un poquito (porque es peligroso si no lo controlas) de BlackHat.
Pero antes de comenzar un par de comentarios para evitar malentendidos…
Siempre que ha sido posible (y si no lo indico) las instrucciones y capturas de pantalla se refieren a la versión 2.0 Beta de Scrapebox, que está muy avanzada y soporta 64 bits entre otras muchas mejoras respecto a la versión 1.
Scrapebox es una herramienta de pago, que no ofrece ninguna demo, si quieres utilizarla debes comprarla. Incluso para utilizar la versión Beta debes tener una licencia.
Y aunque esta guía es muy extensa (¡más de 7.000 palabras!) todavía queda mucho que contar sobre Scrapebox, ya que sólo estoy explicando las funciones que utilizo habitualmente, y que pienso que pueden ser más útiles para el público en general.
¿Estás sentado? Ve pidiéndote una pizza y prepara café y coca-cola… ¡vamos a empezar!
¿Qué es Scrapebox?
 Es una herramienta que te permite rastrear, recopilar y procesar información de forma masiva en Internet. Un programa «de escritorio» sólo disponible para Windows.
Es una herramienta que te permite rastrear, recopilar y procesar información de forma masiva en Internet. Un programa «de escritorio» sólo disponible para Windows.
Digamos que cualquier actividad que puedes hacer manualmente con un buscador, puedes hacerla mucho más rápidamente con Scrapebox, y además crear flujos de trabajo que puedes reutilizar.
Es muy posible que conozcas esta herramienta por su mala reputación, y por estar relacionada con “malas prácticas”, Spam o tácticas BlackHat.
Y sí, puede utilizarse para todo eso, de hecho uno de sus puntos fuertes es automatizar el envío masivo de comentarios en blogs, pero además puede utilizarse para muchas tareas que tienen poco que ver con el BlackHat, como verás más adelante.
¿Por qué hay que pagar por Scrapebox?
Como he comentado al principio, sí o sí hay que pagar para utilizarlo, no ofrece demos, periodos de prueba ni nada parecido.
¿Y cómo puede estar seguro de que funciona bien si no la puedes comprar primero?
Scrapebox funciona, y muy bien, pero debes aprender a usarlo antes de poder sacarle partido. Si tienes dudas de si puede serte útil para tu estrategia particular lee esta guía y toma una decisión. Si después tienes preguntas, para eso están los comentarios 🙂
Aunque no todos lo admiten abiertamente, en parte debido su reputación, muchos SEOs la utilizan de forma habitual, principalmente como apoyo a sus tareas WhiteHat, pero también para ayudarse a posicionar con “otros métodos” 😉
Scrapebox es una de esas pocas herramientas fantásticas que puede servir «para todo”, si la utilizas con un poco de imaginación. Y viene muy bien para aprenden algunos conceptos importantes del posicionamiento web.
Y un detalle muy importante sobre Scrapebox: no tiene programa de afiliación, es decir que nadie gana dinero por aconsejarla, por lo que las recomendaciones suelen ser bien intencionadas.
Afortunadamente es una herramienta económica comparada con otras, se paga 197 USD y listo, sin cuotas mensuales ni pagar por actualizaciones
(Como ya sabes NO es un enlace de afiliado, es un descuento exclusivo del desarrollador)
Interface de Scrapebox
Si ya has utilizado Scrapebox, tal vez desees saltarte esta sección, aunque por otra parte quizá descubras algo que no sabías 😉
Este es el aspecto de Scrapebox v2 (beta) y para alguien que no lo ha visto nunca, sé que puede intimidar un poco.
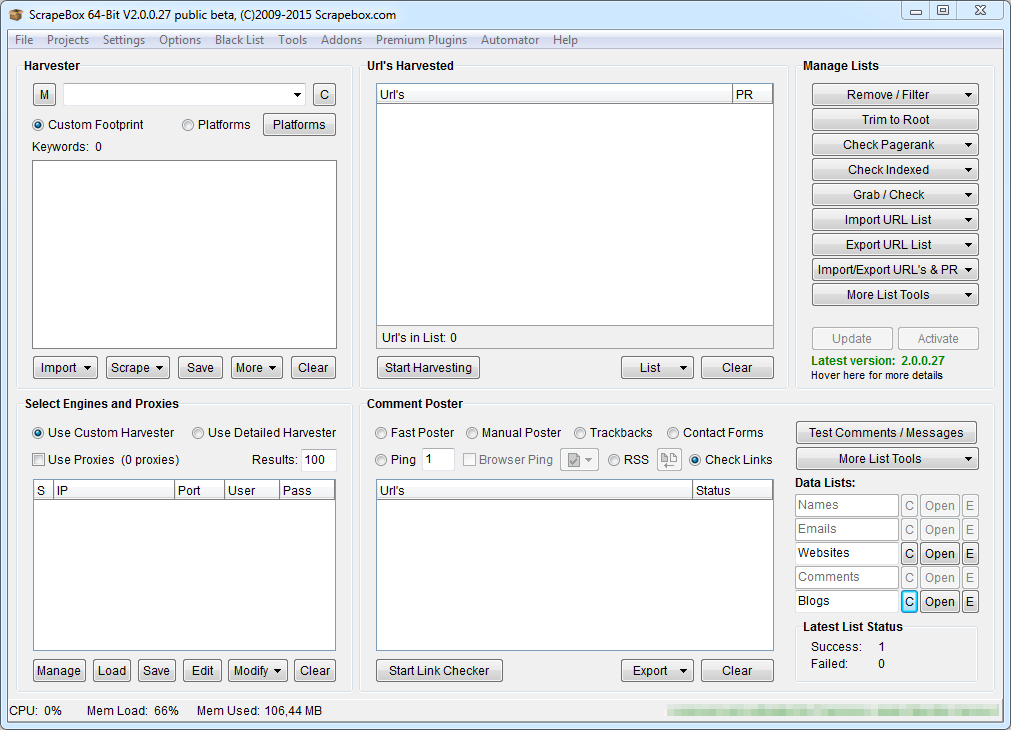
Pero te preocupes, con el uso y la ayuda de esta guía aprenderás a realizar la mayoría de las acciones muy rápidamente.
Estas son las 5 grandes secciones en las que se divide la interface de Scrapebox:
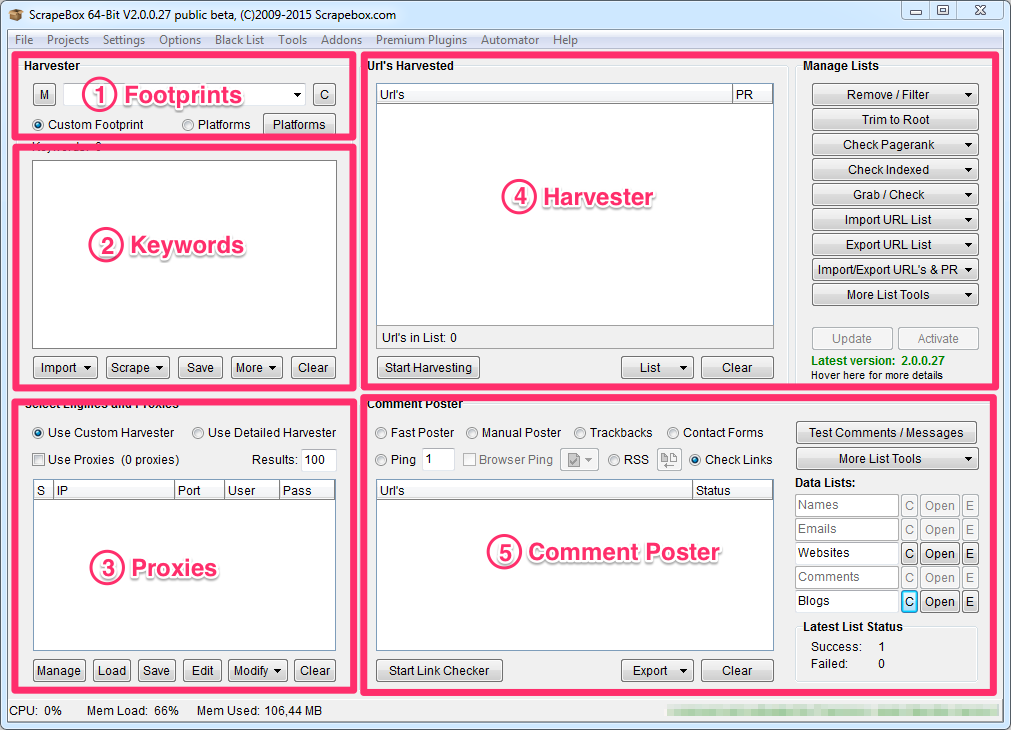
Aunque me gusta utilizar el español siempre que puedo, he decidido conservar la terminología en Inglés a través de esta guía para no confundirte cuando utilices el programa.
FOOTPRINTS
En esta sección introduces los Footprints que deseas utilizar para delimitar tus búsquedas.
Por si no conoces lo que es un footprint: se trata de una “huella” reconocible que podemos utilizar para encontrar algo en internet.
Por ejemplo: seguro que has visto la frase «Proudly powered by WordPress” en el pié de muchas páginas. Ese texto común es una “huella» que te permitiría buscar webs que están construidas con WordPress.
KEYWORDS
Al igual que utilizas palabras o frases para buscar algo en Google, utilizarás esta sección para introducir las Keywords que quieres encontrar mediante un Footprint.
Un ejemplo sencillo: para encontrar artículos publicados en Universidades que hablen de varias dietas para adelgazar podrías poner como Footprint «site:.edu» y como Keywords “dieta para adelgazar, dieta dukan, dieta de la piña, etc.” (cada keyword en una línea)

Con ello Scrapebox haría una búsqueda separada para cada una de estas Keywords en todos los sitios alojados en un domino «.edu», es decir Universidades.
PROXIES
En esta sección eliges el tipo de recolección («harvest») que vas a utilizar, y también, muy importante, gestionarás tus proxies o buscarás nuevos si no tienes.

Pronto descubrirás que para utilizar Scrapebox eficientemente necesitas unos buenos proxies, ya sea para recolectar búsquedas masivas, utilizar varios de los Addons de Scrapebox, o los comentarios automatizados. Pero por ahora no te preocupes, veremos este tema de los proxies en el siguiente bloque.
HARVESTER
En esta sección aparecerán los resultados de tus búsquedas, y podrás gestionarlos mediante los botones de la derecha, que te permiten eliminar duplicados, comprobar el estado de indexación, filtrar los resultados por Page o Domain Authority, MozRank, etc.

COMMENT POSTER
La principal utilidad de esta sección es el envío de comentarios automatizados, pero también la emplearás para indexar tus Backlinks, comprobar si siguen estando vivos, etc.

ADDONS Y PLUGINS
Aunque no forman parte de la interface Principal de Scrapebox, uno de los puntos fuertes de esta herramienta es la cantidad de plugins que tiene (unos pocos son de pago) y que te permiten realizar muchas más tareas.

SETTINGS (AJUSTES)
No voy a explicar aquí los ajustes de Scrapebox 2, porque en principio no necesitarías tocarlos, y la explicación de todos ellos llevaría mucho tiempo.
Pero sí que hay un ajuste que es importante que conozcas.
En el menú superior pincha en “Settings” y luego en «Harvester Engine Configuration”.
Ahí puedes editar los ajustes para varios motores de búsqueda que soporta Scrapebox, y también crear nuevos ajustes.
Por defecto Scrapebox utiliza Google Global «Google.com» para recolectar información, pero si deseas utilizar la versión de Google para tu país, puedes hacerlo editando el ajuste por defecto o creando uno nuevo.
Por ejemplo para utilizar Google España puedes duplicar el ajuste de Google y donde dice “&hl=en” pones “es”, o “mx” para México, etc.

Para que quede claro, en el campo “Query String” donde dice:
«http://www.google.com/search?complete=0&hl=en&q={KEYWORD}&num=100&start={PAGENUM}&filter=0»
Quedaría así para buscar en Google España (.es)
«http://www.google.com/search?complete=0&hl=es&q={KEYWORD}&num=100&start={PAGENUM}&filter=0»
Proxies
Para sacar el máximo partido a Scrapebox necesitas usar proxies, y si vas a utilizar sus funciones más “oscuras” es muy recomendable ejecutar Scrapebox desde un Servidor Virtual Privado (VPS)
Vas a necesitar proxies para realizar peticiones de búsqueda masiva, y también para comprobar el Pagerank, indexado, etc. sin que Google bloquee tu IP por abusar del servicio.
Tienes dos opciones, comprarlos o aprender a encontrarlos tu mismo.
Proxies de pago
No te voy a recomendar aquí ningún proveedor en concreto, puedes encontrar cientos de opciones buscando en Google “buy proxies for Scrapebox” o “comprar proxies”.
En realidad lo que haces es “alquilar” proxies durante un tiempo determinado, normalmente un mes, y al final de este periodo dejarán de funcionar. O si estableces un plan de pagos mensual te mandarán unos nuevos.
Básicamente puedes optar por comprar dos tipos de proxies:
Proxies Compartidos (“Shared” o “Semi Dedicated»)
En esta variante los mismos proxies que te alquilan los ofrecen también a otros compradores, por lo que suelen ser bastante económicos (mínimo 1USD por proxy al mes)
Pueden funcionar bien si no utilizas Scrapebox a su máximo potencial, pero el ratio de éxito en comentarios no suele ser demasiado bueno.
Proxies Privados (“Private” o “Dedicated»)
Estos proxies sólo los utilizarás tú por lo que son mucho más efectivos, pero también más caros, normalmente el doble (mínimo 2 USD/proxy/mes)
¿Cuantos proxies necesitas? Pues depende del uso que le des a Scrapebox
- Si realizas consultas de poco volumen de vez en cuando, y no utilizas el módulo de comentarios automatizados, 10 proxies compartidos suelen ser suficientes.
- Si utilizas Scrapebox intensivamente durante periodos de tiempo largos, o para comentar automáticamente, tendrás más éxito con proxies privados, comenzando con un mínimo de 20.
Proxies públicos
Son aquellos que puedes encontrar en blogs, foros o páginas que publican listas para todo aquel que quiera usarlas.
Lo genial de este método es que los proxies te salen gratis, pero suelen durar muy poco (unas pocas horas) porque muchos como tú los están utilizando a la vez y Google los detecta y bloquea rápidamente.
La forma más sencilla de encontrar y comprobar proxies públicos es precisamente utilizando Scrapebox.
Pincha en el botón “Manage” y luego en “Harvest Proxies” y “Start»
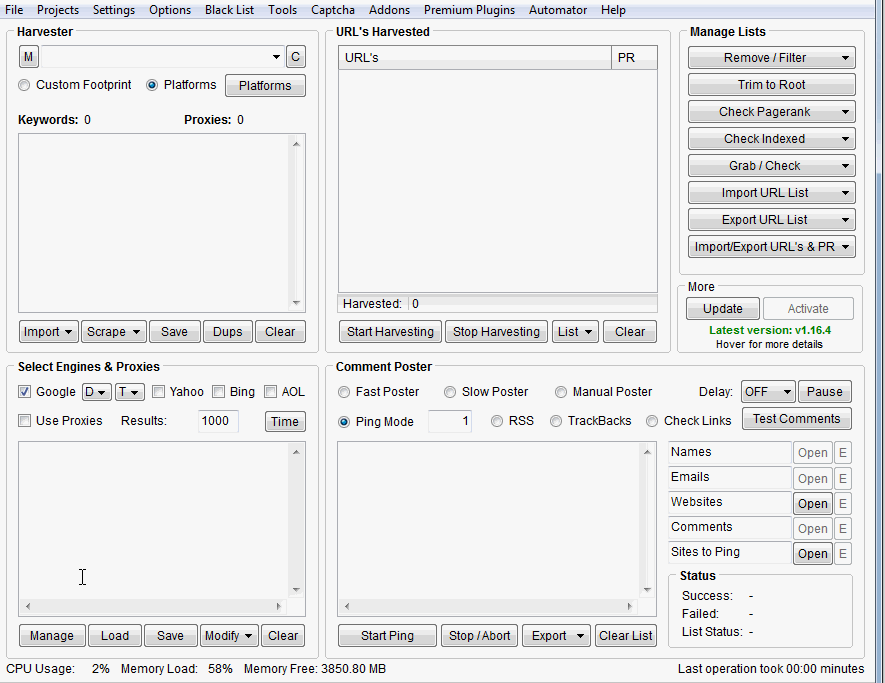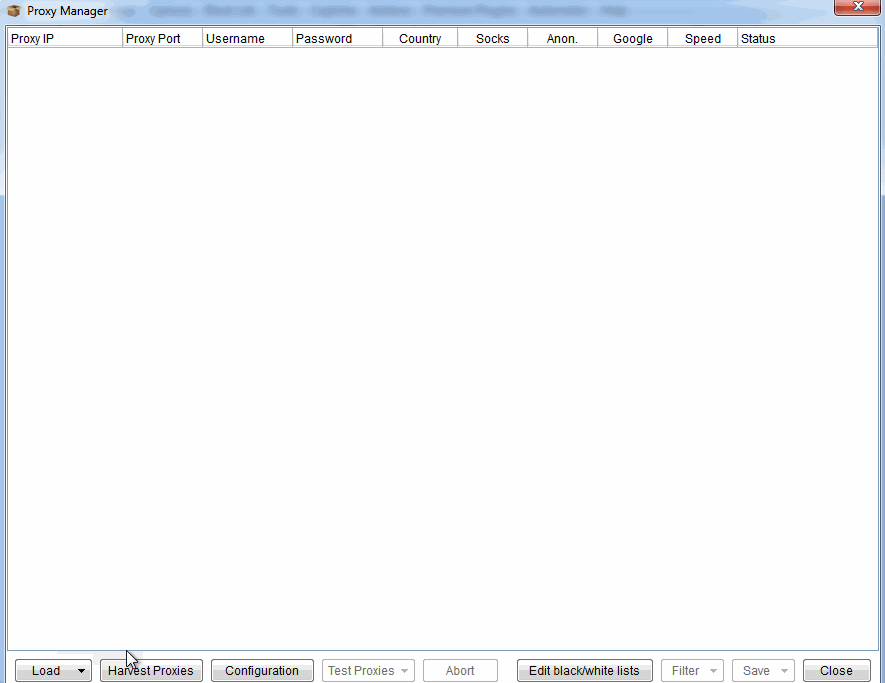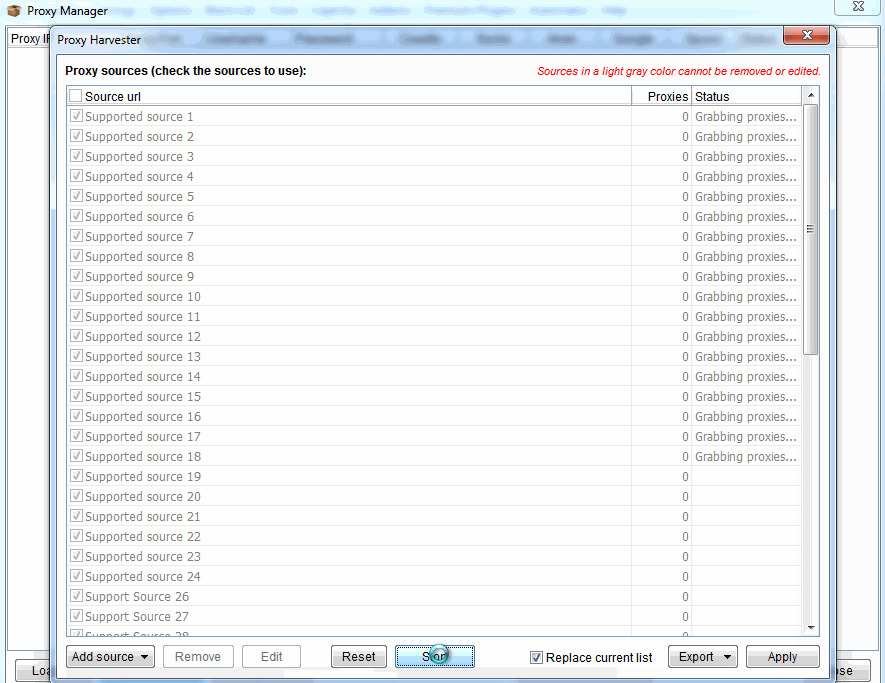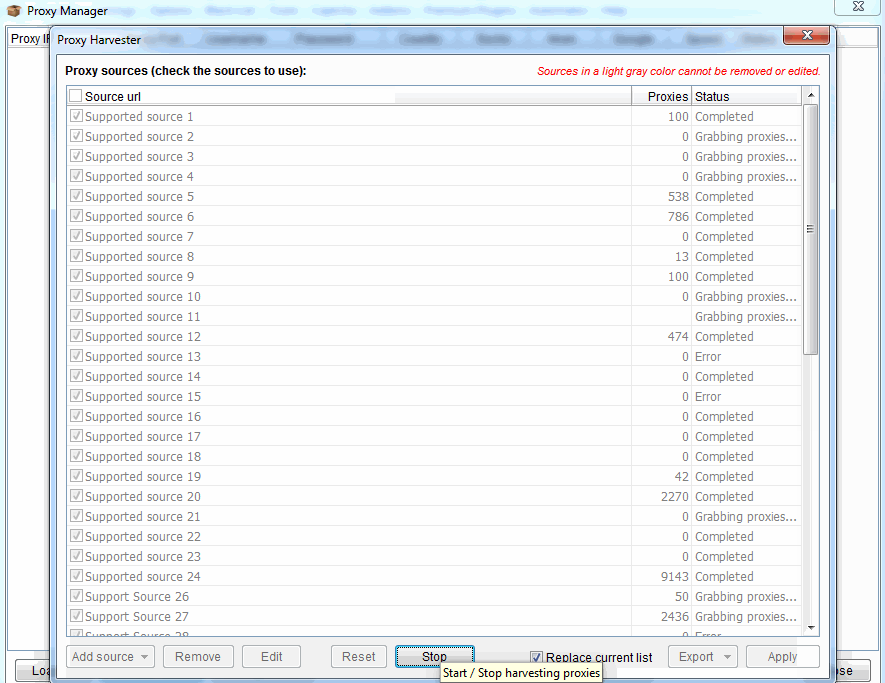
Cuando el Proxy Harvester haya terminado debes comprobar tu lista de proxies.
Pincha en “Test Proxies” y “Test all Proxies»
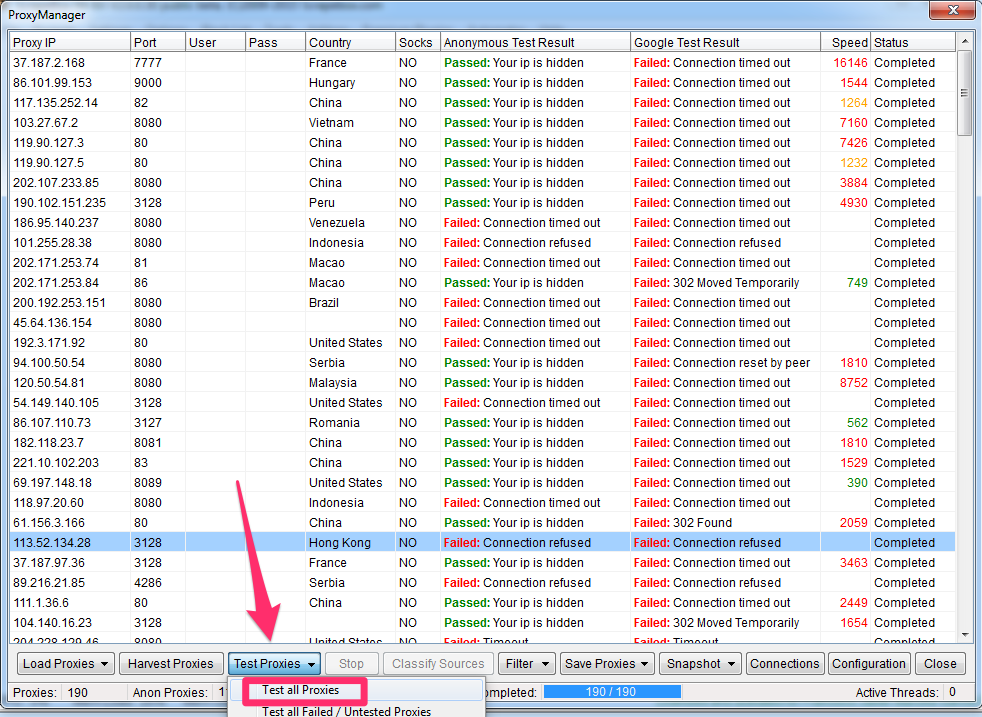
Scrapebox comprueba los proxies y te dices si son anónimos y si funcionarán con Google.
Para trabajar con Google necesitas proxies compatibles con Google (“Google passed”) y descubrirás que no son los más fáciles de encontrar.
Para otros motores de búsqueda, o para comentar, es suficiente con que sean anónimos.
Guarda los dos tipos de proxies en archivos de texto separados, para usarlos según la activad que vayas a realizar.

Si no tienes experiencia encontrando buenas fuentes de proxies yo te recomendaría que no comenzases con proxies públicos, de lo contrario tendrás que recolectar proxies nuevos cada pocas horas y puedes hartarte muy rápidamente.
Para comenzar con lo mejor es comprar un paquete económico de 10 proxies compartidos, y cuando ya tengas más experiencia usando la herramienta es el momento de aprender a buscar proxies por tu cuenta y utilizarlos con el Proxy Harvester

El Proxy Harvester de Scrapebox busca en una lista de sitios que está disponible para todo el que utiliza esta herramienta (y somos muchos) por lo que no es el mejor método para encontrar proxies públicos.
Palabras clave
“Scrapear” es posiblemente la función más utilizada de esta herramienta. Podríamos traducir este término como “arañar” o “rascar” la web, es decir rebuscar para encontrar lo que necesitamos.
Casi cualquier tarea que puedes realizar en Scrapebox comienza con una recolección de datos, así que voy a seguir más o menos el proceso «normal» con un ejemplo ficticio.
Para el resto de este artículo vamos a suponer que estamos interesados en el nicho de “dietas para adelgazar”, y que no sabemos nada o muy poco sobre ese nicho particular.
El primer paso suele ser conseguir una buena lista de palabras clave para trabajar con ella.
Para ello pincha en el botón “Scrape” y “Keyword Scraper” en el menú que se despliega.

A continuación introduce las palabras clave con las que desees comenzar y elige el método y el motor del que quieres recolectar las sugerencias.

Scrapebox puede explorar en segundos las sugerencias que ofrece Google Suggest, Youtube o Bing, entre otros.
En este ejemplo escribe simplemente “dietas para adelgazar”, marca sólo “Google Suggest” y pincha en “Start”. Casi inmediatamente verás que los resultados aparecen en la derecha.

En este ejemplo Scrapebox ha encontrado 11 frases clave únicas (después de eliminar los duplicados) que provienen de las “Búsquedas relacionadas” que muestra Google al final de la página de resultados.
Puedes crear una lista mucho más extensa pinchando en el botón “Append A-Z”. Al hacerlo Scrapebox recolectará todas las sugerencias que encuentre la función auto-completar de Google para todo el alfabeto.

Al hacerlo tu lista se amplía, en este caso a 271 palabras clave. Ahora podrías darte por satisfecho, o seguir expandiendo tu lista pinchando en el botón “Transfer Results to Left Side” y otra vez en “Start”.
Y puedes repetir este proceso tantas veces como quieras, o pedirle a Scrapebox que repita el ciclo automáticamente hasta cuatro veces con la opción “Level»

Si lo que te interesa es una lista de palabras clave con cierto volumen de tráfico (para crear un artículo por ejemplo) puedes analizarlas y filtrarlas con el Planificador de Palabras Clave de Google, de lo contrario continúa con toda la lista tal cual está.
Es una buena idea exportar la lista de Keywords para poderla recuperar más adelante.
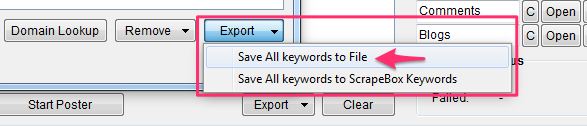
Para trasladar la lista a Scrapebox pincha en «Save All keywords to Scrapebox Keywords»
Pero antes de dejar esta sección hay una opción muy interesante que te ofrece Scrapebox: la posibilidad de comprobar si hay disponibles dominios de palabra clave exacta (EMD) para la lista de palabras clave.
Para ello pincha en “Domain Lookup»

Elige las extensiones que deseas comprobar, pincha en “Start» y Scrapebox te dirá si el EMD está disponible.

¿Para qué puedes utilizar esta función?
Si sabes cómo manejarlo, un dominio exacto todavía puede ser muy efectivo para dominar algunos nichos.
Recolectar con Scrapebox
Ahora que ya tienes una lista de palabras clave, es el momento de que hagas algo con ellas.
Puedes optar, por ejemplo, por comenzar recolectando una lista de webs que publiquen artículos sobre estos temas, para comenzar a conocer el nicho. Y quizá filtrar una lista de esos artículos para destacar aquellos que se comparten más.
También podrías encontrar foros que trataran estos temas, para comenzar a integrarte en ellos y generar ideas, estudiar colaboraciones y publicitar tu web.
O tal vez quieras localizar webs que acepten artículos de invitado (Guest Posts) relacionados con tu temática.
Pero antes debes tener una noción mínima de qué son los Comandos de Búsqueda y cómo funcionan.
En Scrapebox utilizarás estos operadores a modo de Footprints (huellas) para buscar ciertos patrones que se repiten en la información que vas a buscar.
Por ejemplo: las páginas donde aparezca determinada palabra clave en el título, o que estén construidos con un sistema de publicación como WordPress, etc.
LOS OPERADORES BÁSICOS QUE DEBES DOMINAR
inurl
Encuentra las páginas que contienen una determinada keyword en su dirección (URL)
Ejemplo: «inurl:dieta» encontraría páginas que contengan «dieta» en la dirección, como «http://dieta.exur.netdna-cdn.com»
intitle
Encuentra las páginas que tienen la keyword buscada en el título.
Ejemplo: «intitle:dieta» encontraría páginas en cuyo título esté la keyword «dieta» como «SITIO OFICIAL de la Dieta Dukan | Dieta n° 1 en Francia …” como www.dietadukan.es
site
Encuentra páginas alojadas en dominios específicos.
Ejemplo: «site:.edu» encontraría todos los dominios alojados en el TLD «edu»
Y por supuesto es posible combinar varios operadores, como por ejemplo: «inurl:dieta site:.edu».
Puedes aprender más sobre este tema en esta guía de Google en español.
Sigamos con nuestro ejemplo.
Carga la lista de palabras clave que has creado en el campo «Keywords» del «Harvester»
Y busca los primeros 20 resultados de Google (2 primeras páginas) para cada una de ellas.
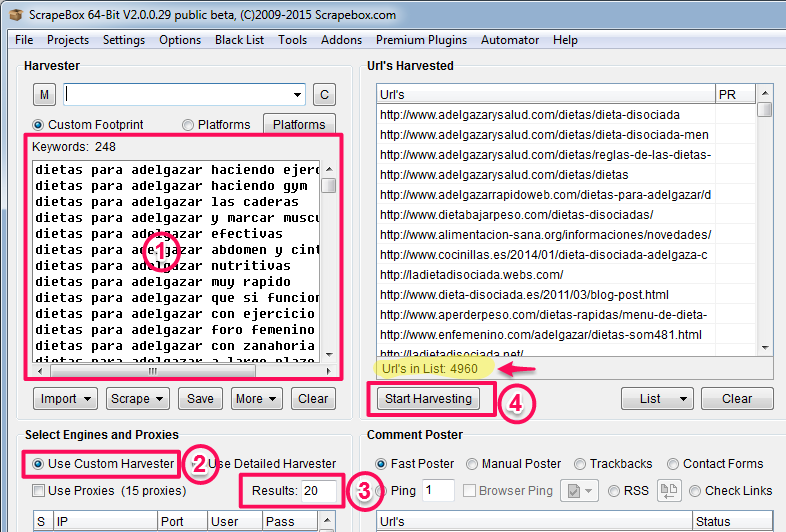
Scrapebox te devuelve 4.960 resultados, es decir 20 resultados de cada una de las 248 keywords que ves a la izquierda.
Verás que no he utilizado proxies (no están marcados), porque el volumen de la «recolección» no era demasiado grande, pero los necesitarás para obtener grandes volúmenes de datos, de lo contrario Google bloqueará tu IP.
Una vez obtenidos los resultados debes eliminar los duplicados. Puedes hacerlo teniendo en cuenta la URL completa o sólo el dominio.
Para nuestro ejemplo elimina los duplicados por URL.
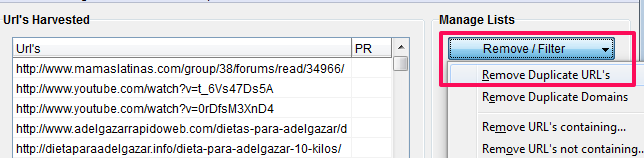
Y te quedas con 2.369 url únicas.
Ahora sería interesante saber cuales de ellas son las que más se han compartido en Redes Sociales, porque teóricamente serán las que tienen contenidos más atractivos para este nicho.
Para ello vas a instalar tu primer Addon: «Scrapebox Social Checker»
Scrapebox Social Checker
El proceso de instalación es el mismo para todos ellos, pincha «Addons» en el menú superior, elige el que deseas instalar y pincha en «Install Addon»
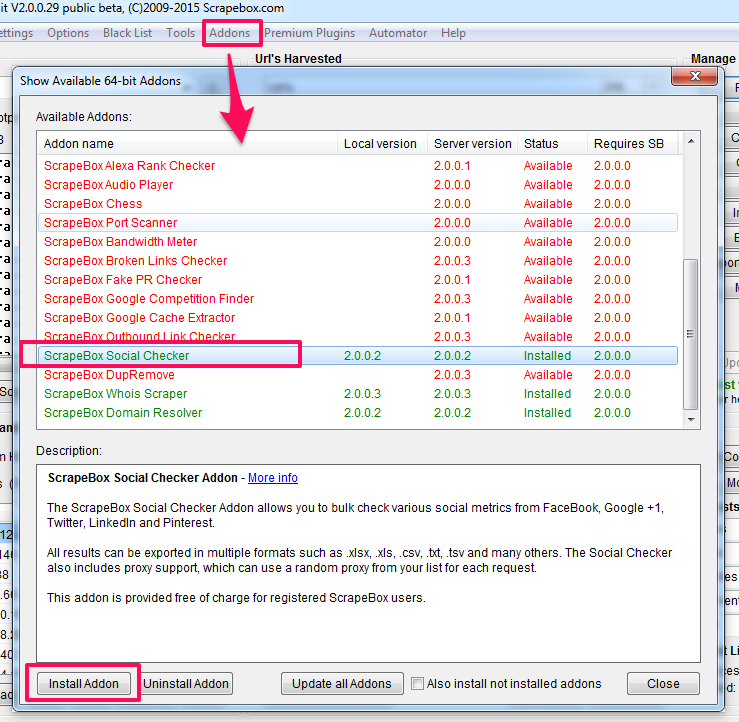
Una vez instalado podrás acceder al Addon desde el menú.

Abre «Scrapebox Social Checker», pincha en «Import urls from Scrapebox harvester» y luego en “Start”.
Enseguida comenzarás a ver el número de veces que las URLs se han compartido en Facebook, G+, Twitter, LinkedIn y Pinterest.

Para analizar los datos con más facilidad, lo mejor es exportarlos a un fichero Excel donde podrás ordenarlos o filtrarlos.
En la mayoría de Addons tienes la opción de exporta los resultados para Excel o como texto simple.
¿Qué consigues con la información que te proporciona Social Checker?
Pues, por ejemplo, saber qué canales de comunicación suelen ser los más importantes para este nicho, o lo que es lo mismo, por dónde se mueven los usuarios.
Y esta información te ayudará a comprender qué tipo de contenido tiene mejor aceptación en tu nicho, y te será más fácil replicarlo.
Merge y vencerás (función Merge)
Para crear búsquedas avanzadas existe una potente función que poca gente utiliza: el botón “M” (“Merge”)
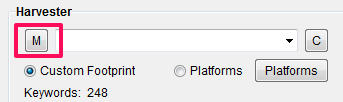
Para usar Merge debes crear una lista de Keywords en un fichero de texto y añadir el operador «%KW%» que referenciará a las Keywords que tienes en Scrapebox.
¿Vaya lío no? Tranquilo, con un ejemplo lo entenderás enseguida.
Digamos que para tu nicho de dietas se te ocurre buscar todos los blogs que escriban sobre tu lista de keywords y que funcionen en WordPress o Drupal porque planeas comentar en ellos.
Y sabes que puedes encontrar webs que funcionen con estos motores buscando «powered by wordpress” o «powered by Drupal»
¿Pero como puedes combinar estos dos Footprints con tu lista de Keywords?
Pues con la función Merge, claro.
Crea un fichero de texto que contenga estas dos líneas y guárdalo.
“powered by WordPress” %KW%
«powered by Drupal» %KW%
Pincha en el botón «M» y elige este fichero. Automáticamente Scrapebox combinará los dos footprints con las keywords de esta forma:
“powered by WordPress” “dietas para adelgazar en 3 días”
«powered by Drupal» “dietas para adelgazar en 3 días”
“powered by WordPress” «dietas para adelgazar muy rápido”
«powered by Drupal» «dietas para adelgazar muy rápido”
… y así con todas las keywords
Comenta en blogs
Una de las estrategias SEO más conocidas es comentar en blogs para conseguir enlaces y visibilidad. Y Scrapebox está especialmente preparado para esto.
Imaginemos que decides probar esta estrategia con la lista de páginas que ya has encontrado para tus Keywords.
Naturalmente, no todas ellas serán blogs, ni todas las que lo sean admitirán comentarios.
Afortunadamente Scrapebox está preparado para esto y mucho más 😉
Blog Analyzer
¿Quieres saber rápidamente en qué páginas puedes comentar? Utiliza el Addon “Blog Analyzer”.
NOTA: todavía no está disponible para la versión 2.0 beta, por lo que tendrás que utilizar la versión 1.
Este Addon te permite saber qué plataforma utiliza la página en cuestión (por ejemplo WordPress), si admite comentarios, tiene protección anti-spam o utiliza captchas.
Elige “Scrapebox Blog Analizer” del menú “Addons”, importa la lista a comprobar desde “URL’s Harvested” y pincha en “Start»
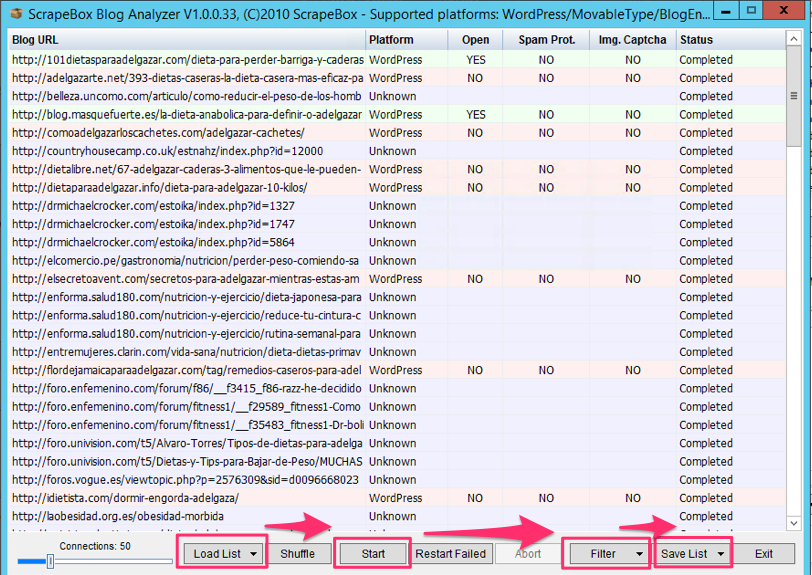
A continuación puedes filtrar la lista por blogs que no acepten comentarios, o aquellos que pidan un código de verificación (“captcha”), y devolver la lista depurada a Scrapebox, o guardarla para utilizarla más adelante.
Y si lo deseas puedes continuar depurando tu lista de blogs “buenos”, centrándote únicamente en aquellos que tengan pocos comentarios, comprobando el número de enlaces salientes con el Addon “Outbound Link Checker”.
Outbound Link Checker
Carga la lista de URLs con el botón “Import urls”, elige “Import urls from Scrapebox harvester” y pincha en “Start»
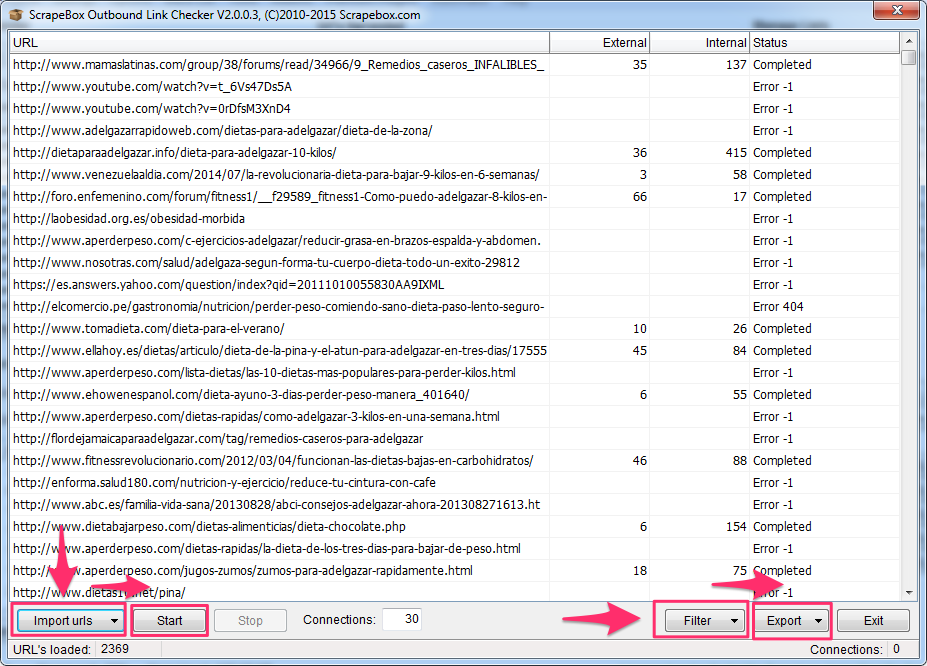
A continuación utilizar el botón “Filter” para seleccionar las URLs que dan error (“Remove failed/error entries”) y elimina aquellas que tengan más de un número de enlaces que consideres excesivo.
¿Porqué puedes querer no comentar en blogs con muchos enlaces salientes?
En primer lugar porque normalmente (aunque no siempre) los blogs que tienen una gran cantidad de comentarios suelen estar llenos de Spam, y Google se dará cuenta tarde o temprano y puede penalizar o disminuir la efectividad de los enlaces.
Y también porque a mayor cantidad de enlaces salientes, los beneficios que proporciona un backlink disminuyen. Aunque este punto es un poco controvertido y yo personalmente no me fijo un límite de enlaces, sino que observo lo que suele ser “normal” en cada nicho.
Una vez depurada tu lista puedes plantearte bombardearla con comentarios automatizados (lo veremos en un momento) o utilizarla para comentar manualmente.
¿Porqué te podría interesar perder el tiempo comentando de forma manual, cuando puedes hacerlo automáticamente con Scrapebox?
Te puede interesar si tu intención es crear una web “legal” y vas a apuntar los enlaces directamente a tu sitio.
A continuación te comento algunas formas en que Scrapebox te puede ayudar para comentar sin spamear blogs.
Alexa Rank Checker
Con los comentarios adecuados puedes conseguir tráfico y visibilidad en blogs de referencia en tu nicho, siempre que leas detenidamente cada artículo y aportes un comentario que contribuya a enriquecerlo.
Para ayudarte a invertir mejor tu tiempo carga tu lista en el Addon «Alexa Rank Checker” y conocerás rápidamente las estadísticas de tráfico de cada dominio.
![]()
Recuerda que cuanto más bajo el número más tráfico recibe la página, y que los datos de Alexa (excepto para dominios verificados) son sólo una estimación, pero en cualquier caso útil para comparar dominios entre sí.
Dofollow/Nofollow
Si te interesa conseguir algún enlace Dofollow en un blog de referencia en tu nicho, utiliza el Addon “DoFollow/NoFollow Check”.
NOTA: de momento sólo está disponible para la versión 1 de Scrapebox.

Dependiendo del nicho será complicado encontrar Blogs que permitan comentarios con enlaces Dofollow, pero si insistes puedes acabarás encontrando alguno.
Page Authority
Ya sé que hay mucha controversia al respecto, pero estoy convencido de que un comentario «bien puesto» puede ayudarte aunque sea Nofollow.
El Addon “Page Authority” te permite extraer las métricas Page Authority, Domain Authority y MozRank utilizando la API de Moz.
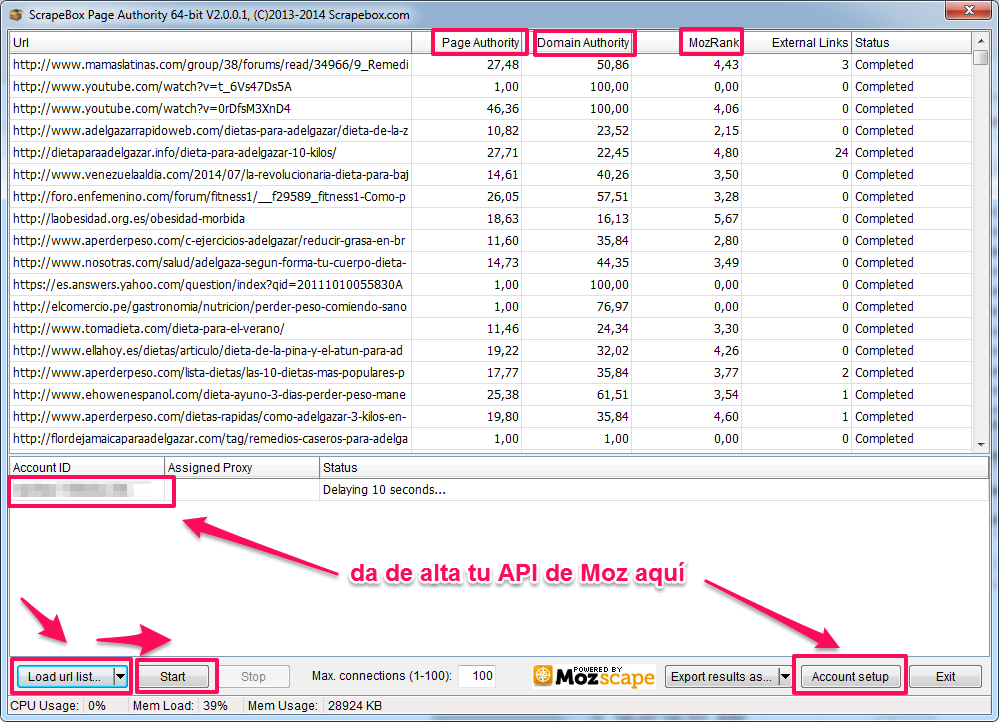
Primero debes dar de alta una API en Moz, utilizando el botón «Account Setup«. Puedes utilizar una API gratuita, aunque si trabajas con listas grandes trabajarás mejor con una API de pago.
Comentarios automatizados

Scrapebox te permite comentar de forma automática en miles de páginas, para conseguir enlaces, tráfico, o las dos cosas.
ATENCIÓN: ¿Seguro que quieres hacer esto? Piénsatelo antes, porque puedes penalizar tu web si no tienes cuidado.
Esta técnica es puro BlackHat, y lleva tiempo perfeccionarla, así que no te apresures, y sobre todo no la utilices si no estás seguro de lo que estás haciendo.
Hasta que no tengas bastante experiencia, y aún así no lo aconsejo, no dirijas ningún enlace creado con Scrapebox o ninguna otra herramienta automática a tu sitio principal («money site»), enlaza a otras Páginas Satélite (Tier 2 ó Tier 3)
Como ya te habrás dado cuenta la mayoría de los blogs que admiten comentarios están moderados, esto quiere decir que el editor o el dueño del blog revisan los comentarios antes de publicarlos.
Estos blogs que llamamos «moderados» no te interesan para esta estrategia, pero puedes guardarlos para analizarlos y de forma manual en los más interesantes, como te he explicado en el punto anterior.
Para la estrategia de comentarios automatizados te interesan los blogs no moderados, que aprueben los comentarios automáticamente, de lo contrario tu porcentaje de éxito será muy pequeño.
Si ya has creado una lista de blogs en los pasos anteriores puedes utilizarla ahora y si no tienes tiempo, y no te importa invertir algo de dinero, puedes comprar alguna lista de blogs no moderados. Seguro que te resulta fácil encontrar algún vendedor.
Si decides utilizar tu propia lista el método más sencillo es probar a comentar y depurar los resultados.
¿Cómo? Te lo explico paso a paso.
- En primer lugar elimina las URL duplicadas (Remove/Filter > Remove Duplicate URL’s) porque no obtendrás ningún beneficio comentando varias veces en la misma página.
- A continuación debes crear los archivos de datos que necesitarás para utilizar el módulo de comentarios. En realidad son los mismos datos que utilizas para comentar manualmente en cualquier blog, pero en cantidad.
- Fíjate en el lateral derecho del módulo “Comment Poster”, y verás que en el apartado “Data Lists” te indica los ficheros que debes rellenar
Los botones son para limpiar cada lista de datos (C), abrir un fichero ya guardado en el disco (Open) o Editar las listas (E)
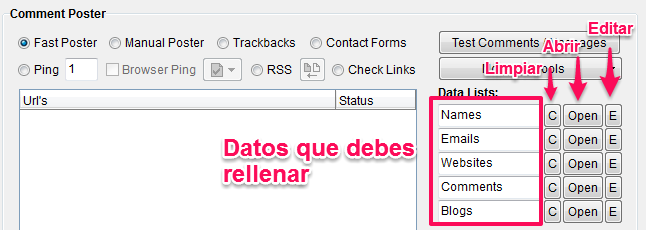
Nombres
En el momento de hacer un comentario siempre te piden un nombre, que se convierte en el texto ancla de tu enlace.
Puedes crear automáticamente una gran cantidad de nombres con el generador automático de Scrapebox, utilizar tus Keywords, o combinar ambos datos.
Personalmente me inclino por incluir diferentes porcentajes de nombres, Keywords, y textos ancla genéricos.
En la barra de menú de Scrapebox pincha en “Tools” y después “Name and Email Generator«. Elige la cantidad de nombres que necesitas, pincha en “Generate” y guarda los resultados como «Names.txt»

Emails
Al igual que el nombre es obligatorio introducir un email para comentar en la mayoría de los blogs, así que genera la misma cantidad de emails con el «Name and Email Generator“, y guarda la lista como «Emails.txt»

Websites
Cuando comentas en un blog habitualmente te piden la dirección de tu sitio web, que se convertirá en un enlace cuyo texto ancla será el nombre que has proporcionado.
¿No me he explicado bien? Veamos un ejemplo tomado de este mismo blog:
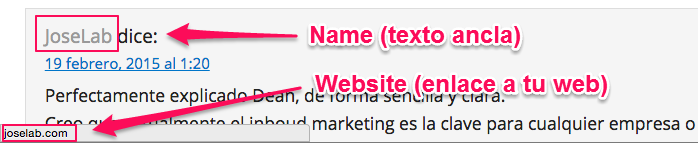
Si estás intentando posicionar o conseguir tráfico para una página concreta deberás poner únicamente esa dirección en el fichero. Si estás creando enlaces para varias páginas escribe las direcciones (una por línea) y Scrapebox las usará aleatoriamente.
Graba este fichero como «Websites.txt»
Comentarios
Ahora debes crear una lista de comentarios para que se envíen de forma automática.
Ten en cuenta que, aunque los comentarios se aprueben de forma automática, el editor puede revisarlos y borrar los comentarios más fuera de lugar.
El nivel de calidad de los comentarios que generes depende del tiempo de que dispongas, y de la calidad que suelen tener en tu nicho particular, aunque por regla general si inviertes un poco de tiempo en ellos los resultados suelen ser mejores.
Un enlace tiene que «aguantar» el tiempo suficiente para que sea plenamente efectivo. Si es borrado poco después de publicarlo no ha llegado a su máxima potencia, a menos que esté en un dominio con mucha autoridad.
Te pongo unos ejemplos relacionados con la temática de dietas, suponiendo que quieres enlazar a una de tus páginas que tratan sobre la «dieta Dukan»
“muchas gracias por el artículo, he venido buscando información sobre la dieta dukan para adelgazar, porque tengo entendido que es la mejor dieta de todas.»
“estupendo artículo, la verdad es que la dieta que más que ha funcionado es la dukan»
“felicidades por tu web ¿qué sabes de la dieta dukan? estoy muy interesado en conocer más, mis amigas dicen que muy buena para adelgazar»
… y bueno ya te vas haciendo la idea, ¿verdad? Por supuesto tendrás que adaptar el tono y la expresión según tu nicho.
Graba este fichero como «Comments.txt»
Blogs
Y por último necesitas una lista de blogs en los cuales insertar tus comentarios.
Si todavía la tienes en el Harvester pincha en el botón “List” y luego en “Transfer URL’s to Blogs List for Commenter»

O crea tu propio fichero y guárdalo como «Blogs.txt»
Blogs con confirmación automática
Como ya sabes lo ideal es contar con una lista de blogs que confirmen automáticamente los comentarios («autoapprove»)
Por desgracia (a menos que hayas comprado una lista) la única forma de distinguirlos es probando.
Antes de continuar recuerda que para este paso necesitas proxies. De lo contrario los sistemas de protección tipo Askimet pueden bloquear la IP de tu ordenador y tu porcentaje de éxito será mínimo.
Además tu nivel de éxito en este proceso también dependerá de la calidad de tus proxies.
Fast Poster
Ahora carga todos los ficheros de datos (Names, Emails, Websites, Comments, Blogs) que has creado anteriormente, selecciona “Fast Poster” y Pincha en “Start Poster»
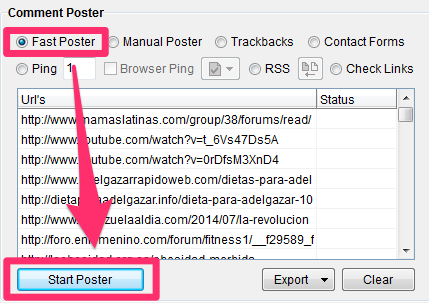
En la pantalla siguiente pincha en el botón “Start” y al rato verás las páginas en las que Scrapebox ha tenido éxito comentando (“Success”) o no (“Failed”)

Si dispones de un programa Anti-Captcha, o pagas por alguno de estos servicios online, puedes utilizarlo para comentar automáticamente en blogs que tengan esta protección.
Si es así pincha en el botón “Decaptcher Setup” y rellena tus datos.
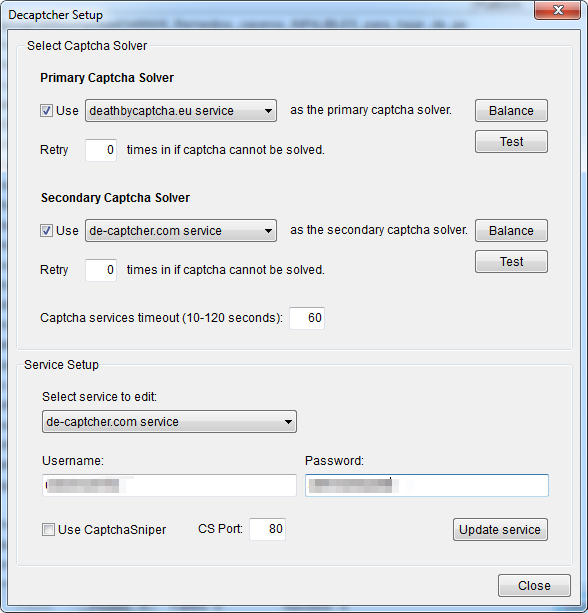
De momento te aconsejo que no te preocupes por este tema, ya te ocuparás de los blogs con protección cuando domines Scrapebox y te merezca la pena invertir en uno de estos sistemas.
Cuando hayas finalizado esta ronda, regresa al interface principal de Scrapebox y exporta los blogs exitosos (“Export all successful entries”) y los que no (“Export all non successful entries”) en archivos separados.

Y vuelve a seguir el mismo proceso con los que han fallado en la primera ronda.
Y haz una tercera, y…
Cuando en una de las rondas consigas muy pocos resultados positivos (“sucsessful”) es el momento de terminar.
Pero… todavía no cantes victoria 🙂
Todo lo que sabes en este punto es que Scrapebox ha podido comentar en estos blogs, pero no si el comentario ha sido aprobado.
Link Checker
Coge tu lista de comentarios exitosos, métela en el archivo “Blogs List”, selecciona “Check Links” y pincha en “Start Link Checker»
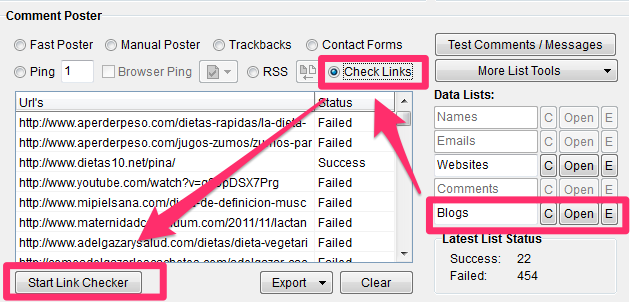
Los enlaces que den éxito (“Success”) son los blogs en los que Scrapebox ha podido comentar automáticamente. Guarda esta lista para utilizarla más adelante.
¡Y por fin tienes tu propia lista de blogs con confirmación automática («auto approve”)!
RECURSO NINJA: hay otras formas de encontrar blogs con confirmación automática, en la página de recursos al final donde te explico alguna más.
¿No ha sido tan complicado, verdad?
Indexa tus backlinks
Has conseguido crear una lista “auto approve” y has comentado en ella.
¡Buen trabajo!
Pero te falta una cosita más 🙂
Si los enlaces que has creado no se indexan en los buscadores es como si no existiesen.
Puedes optar por esperar un tiempo para ver los buscadores los indexan de forma natural, o intentar forzar el indexado inmediatamente.
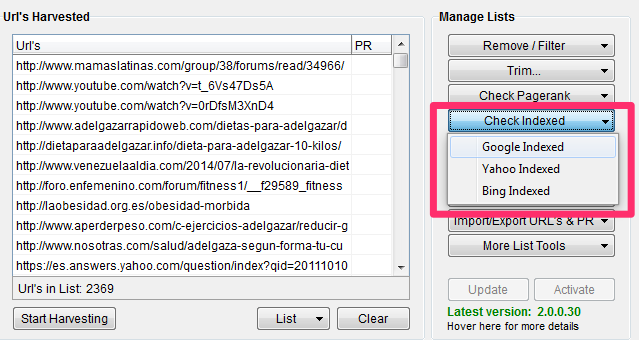
Scrapebox ofrece la posibilidad de forzar el indexado masivo de URLs mediante varios métodos: RAPID INDEXER, PING MODE o RSS.
Sólo te voy a explicar el Rapid Indexer, que es sencillo y seguramente te será suficiente.
Scrapebox Rapid Indexer
Abre el Addon “Scrapebox Rapid Indexer” (disponible sólo para versión 1)
Carga la lista de URLs que deseas indexar (en tu caso la lista de enlaces comprobados), la lista de sitios que quieres utilizar para indexar tus enlaces, y pincha en “Start”

Scrapebox ya viene con una lista de sitios que puedes utilizar para el indexado, y que puedes descargar directamente desde el menú de instalación del Addon.
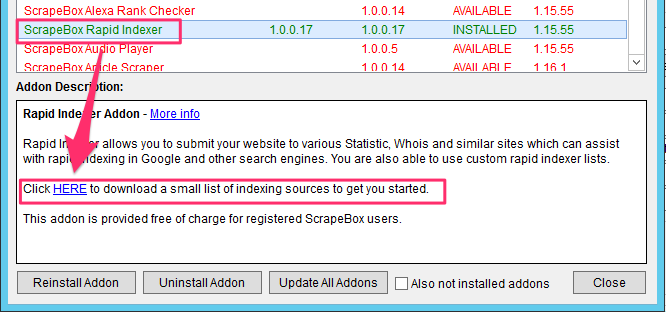
Si descargas el fichero y lo abres verás que contiene una lista de URLs como esta:
http://whois.domaintools.com/{website}
http://hosts-file.net/default.asp?s={website}
http://www.aboutus.org/{website}
Como habrás adivinado este Addon crea páginas temporales en webs de estadísticas, whois, etc. que «enlazan a tus enlaces»
Estas páginas se crean en sitios que son visitados e indexados muy a menudo por los buscadores ,y por ello hay muchas posibilidades que que sigan el enlace y lo indexen.
Análisis de Meta-Tags
Si estás familiarizado con el SEO On Page ya sabrás lo importante que es optimizar el título y la descripción de tus páginas.
Debes comprobar rutinariamente tus meta tags, verificar que los títulos no son demasiado largos, que no falte una descripción, etc. Y algo igual de importante, pero no tan explotado: además de verificar tus metas también es útil controlar los de tu competencia.
¿Porqué? Porque puedes aprender muchas cosas.
Puedes aprender qué es lo que están promocionando y mediante qué palabras clave, y conseguir ideas para crear tus propios artículos.
O analizar los metas de tu competencia para crear los tuyos.
Y si tienes experiencia con Excel puedes hacer maravillas con estos datos 😉
Por ejemplo podrías exportarlos en una hoja de cálculo, borrar las “palabras vacías” y los duplicados, y utilizar Rank Tracker para ver cómo se está posicionando tu competencia.
Comprobación de Metata Tags
Si quieres comprobar tus metas utiliza el Footprint “site:tusitio.com” (por ejemplo “site:ninjaseo.es”)

Y recolecta los meta de las páginas encontradas pinchando en el botón “Grab / Check” y luego en «Grab META info from harversted URL List»
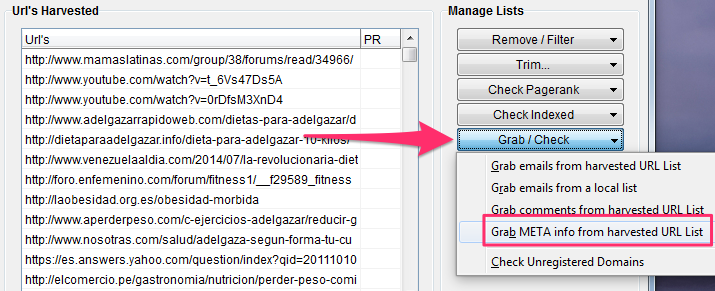
En pocos segundos tendrás los resultados:
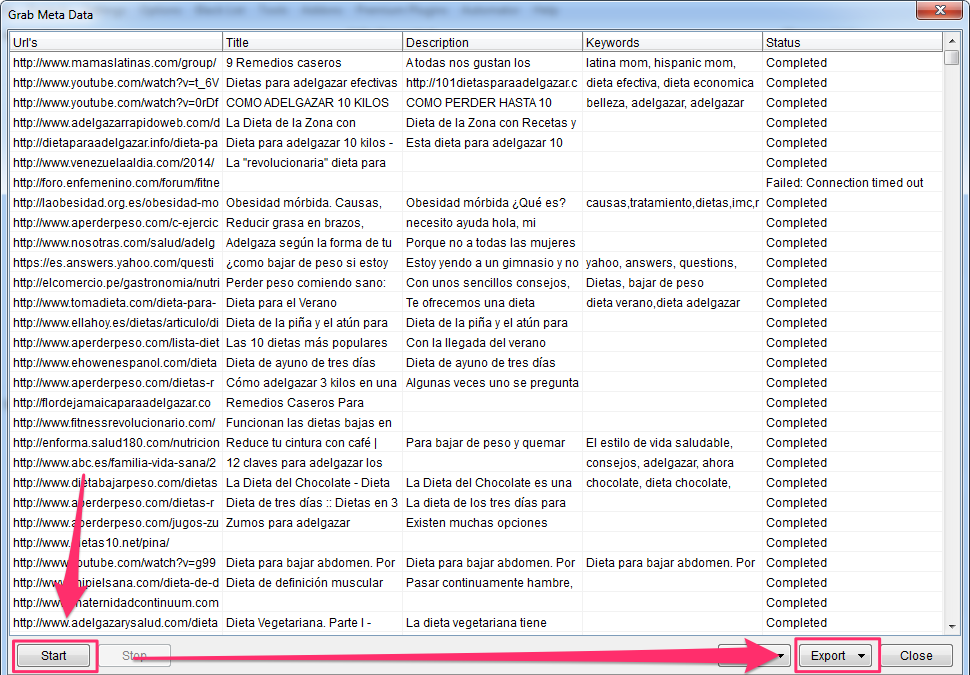
Y podrás exportar estos valiosos datos para analizarlos tranquilamente.
Enlaces rotos y «Broken Link Building»
El Addon “Broken Links Checker” te permite comprobar que no hayan enlaces rotos en tu sitio web, pero también te puede ayudar a conseguir enlaces con la técnica del “Broken Link Building”.
Este método consiste en informar al dueño/editor de una web de algún enlace roto y sugerir que lo sustituya con otro enlace a nuestras páginas.
Como siempre, comienza recolectando las páginas donde quieres utilizar el Addon.
Sitemap Scraper
Si las webs que deseas comprobar tienen un Sitemap puedes extraer todas sus páginas con el Addon “Sitemap Scraper”.
Carga una lista de URLs en el Addon, pincha en el botón “Trim to root and add sitemap.xml” y pincha en “Start»
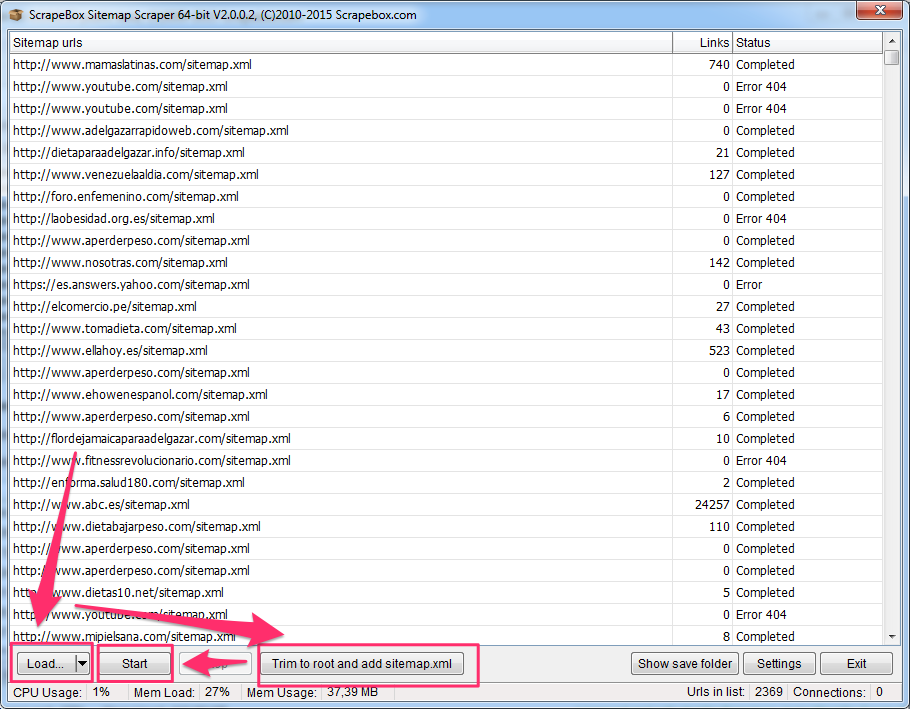
También puedes hacerlo con el Footprint “site:”
Si utilizas diferentes métodos o varios buscadores elimina los duplicados antes de continuar.
Ahora utiliza el Addon “Broken Links Checker” y exporta en las páginas que devuelven un error 404 (no se encontró la página)

¿Qué puedes hacer con esta información?
Si se trata de tu propio sitio web o de tu cliente, repara los enlaces rotos.
Si estás haciendo “Broken Link Building” contacta al editor/webmaster de las webs donde hay enlaces rotos, comunícale el problema y aprovecha para insinuar (esto es todo un arte) que enlace a una de tus páginas.
Artículos de invitado (Guest Posting)
Escribir para otras páginas, lo que se conoce como “Guest Posting” puede ser muy efectivo, si eliges bien el tema y la web.
Esto que estás leyendo es un Guest Post, y además de enseñarte me estoy promocionando y estableciendo una relación contigo, así que puede ser útil, ¿verdad?
Para encontrar páginas que acepten publicar artículos de invitado puedes comenzar buscando con estos Footprints:
“guest post»
“guest blogger»
“post invitado»
“escribe para nosotros»
“envía tu post»
“contribuye»
Por ejemplo: inserta «intitle:»post invitado” en la casilla de “Custom Footprint”
Y las keywords «dieta” y “dietas” en el área de Keywords
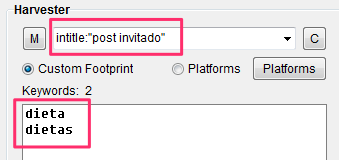
Una vez tengas tus resultados, extrae el dominio raíz con Trim to Root” y elimina los duplicados.

Ahora podrías filtrar los dominios por tráfico con el Addon “Alexa Rank Checker” o por autoridad con «Page Authority” (o ambos) y centrarte en los mejores.
Una vez tengas claro para quien te interesaría escribir, puedes intentar encontrar emails de contacto pinchando en el botón “Grab/Check”, y después en “Grab emails from harvested URL list”

En la práctica verás que no siempre consigues encontrar emails con este método, pero como normalmente estás trabajando con miles de resultados suele ser suficiente.

Ahora es cuestión de que exportes los resultados, contactes con los dueños de las páginas, y explores la posibilidad de escribir en su blog.
Dominios caducados (Expired Domains)
¿Sabías que Scrapebox también te puede ayudar a encontrar dominios caducados?
¿Que no sabes qué puedes hacer con un dominio caducado («expired»)?
Pues puedes hacer muchas cosas, entre ellas montar una PBN o comenzar un proyecto con un dominio «establecido» en lugar de hacerlo con uno «desde cero»
El Addon que vas a utilizar para esto es el «TDNam Scrapper«, y funciona explorando los dominios expirados de Godaddy que no han sido adquiridos en una subasta.
TDNAM son las siglas de «The Domain Name Aftermarket”, y para acceder y registrar dominios en este «mercado» debes pagar una tarifa anual de $4,99.
No es habitual encontrar maravillas en el TDNAM, pero sí que es posible conseguir algún domino decente, a un precio muy interesante.
Lo primero es escribir en el Addon una o varias palabras clave, o puedes cargar tu lista desde la sección de Keywords.
Escribe por ejemplo “dietas” y “dieta” y pincha en «Start»

Enseguida verás los dominios caducados disponibles para tus palabras clave. Visita las subastas de Godaddy para registrarlos.
Además el Addon te muestra unos datos muy interesantes: tráfico (si lo tiene), edad y precio de venta.
Cuidado, no corras a registrar ningún dominio sin antes asegurarte de que está limpio de Spam, y que tiene por lo menos unas métricas decentes.
Si estás familiarizado con las subastas de Godaddy sabrás que puedes conseguir esta información directamente en su página. La ventaja de este Addon es que filtra rápidamente los dominios con compra directa para muchas keywords a la vez.
Y además puedes descargar estos datos para continuar analizando los dominios con Scrapebox u otras herramientas.
¿Necesitas imágenes? Scrapebox al rescate
Scrapebox tiene algunos Addons que en principio pueden parecer una chorrada, pero que en realidad son muy útiles.
El Addon “Google Image Grabber” es uno de ellos.
Seguramente has realizado alguna búsqueda de imágenes en Google, para encontrar inspiración, utilizar alguna imagen en tus artículos, o ilustrar algún PDF, Powerpoint, etc.
Con este Addon puedes hacerlo mucho más rápidamente, y con más control.
Introduce tus Keywords, o cárgalas desde Scrapebox, elige la cantidad de imágenes que deseas encontrar para cada Keyword, su tamaño y el tipo de licencia.
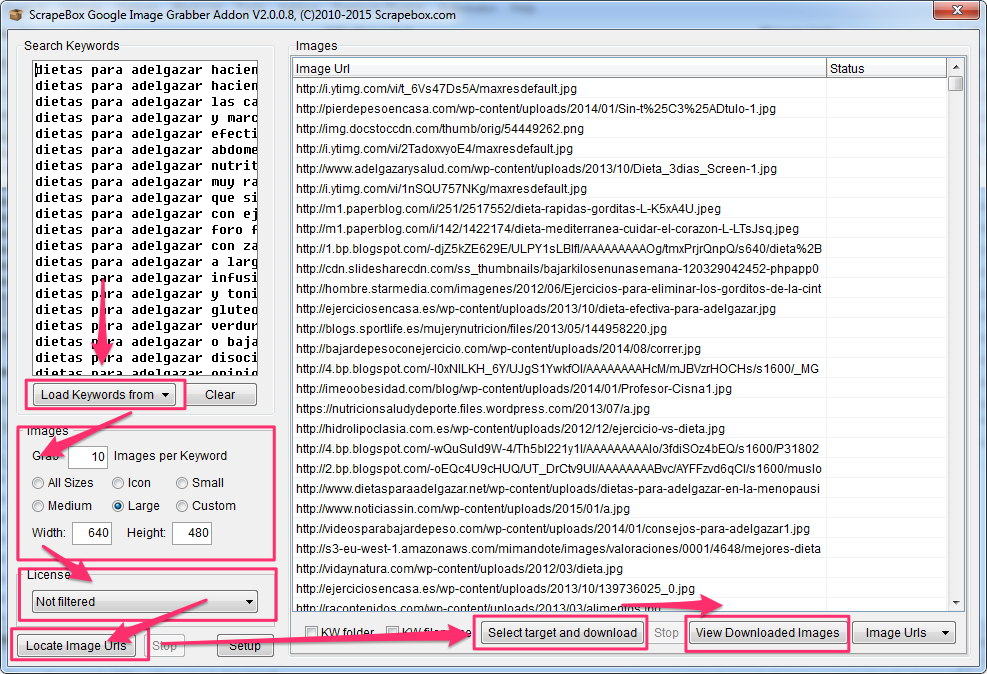
Scrapebox recolectará las URLs de todas las imágenes, y hasta las puedes guardarlas en diferentes carpetas para cada Keyword.
¿No te convence?
Bueno, piensa por ejemplo que necesitas imágenes para crear un montón de artículos “basura” para un Tier 3… pues aquí las tienes, y lo mismo si necesitas crear Páginas Satélite con imágenes, tipo Tumblr.
Y por supuesto puedes utilizar estas imágenes para todas tus actividades creativas, aunque recuerda utiliza el filtro de licencia para evitar problemas.
Escaneo de páginas
En mi opinión el Addon “Page Scanner” es uno de los más interesantes, y por ello me sorprende lo poco que se habla sobre él.
Este Addon analiza una lista de URLs y busca Footprints en el código fuente (HTML)
¿Para qué? Piensa un poco y luego te doy pistas.
Lo primero es tener una lista de URLs para escanear, y decidir que footprints te interesa localizar.
Carga el Addon, crea un nuevo archivo de Footprints y edítalo.
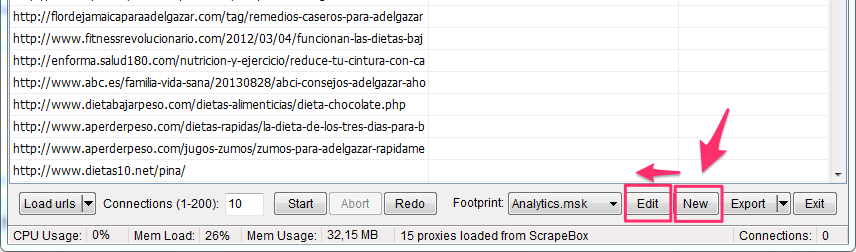
Puedes crear una gran variedad de footprints y categorizarlos para separar distintas páginas según pertenezca a una u otra categoría.
Te voy a mostrar un ejemplo muy sencillo para que vayas comprendiendo sus posibilidades.
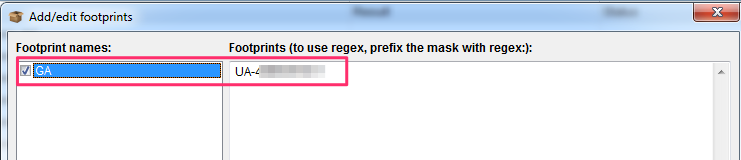
Imagina que te gustaría comprobar si todas las páginas de tu web (para este ejemplo la mía: ninjaseo.es) tienen el código de Google Analytics instalado.
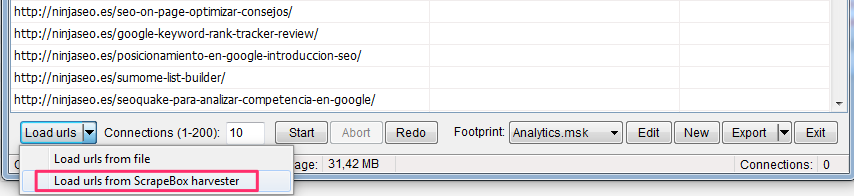
En lugar de visualizar el código de todas las páginas y buscarlo, puedes recolectar todas las URLs de tu web (comando «site:»)

Cargar la lista en el Addon «Page Scanner»
Crear una categoría, que podrías llamar “GA” para abreviar, con el código de Analytics que debería estar presente en cada página.
Pinchar en “Start”, y comprobación realizada:

En este caso sólo has utilizado un grupo de footprints (GA), si tuvieras varios grupos el Addon los analizaría todos y te diría en qué páginas ha encontrado el footprint (Completed)
Venga, un par de ideas más.
Utilízalo para analizar grandes volúmenes de URLs, descubriendo pautas, plugins similares… tu imaginación es el límite 😉
Por ejemplo puedes recolectar los dominios de un nicho concreto y averiguar si tus competidores están monetizando con Adsense.
¿A que te gusta este Addon?
Análisis rápido de la competencia en las SERPS
Si todavía estás leyendo (¡bravo!) te habrás dado cuenta de que Scrapebox es una especie de navaja suiza, que puedes utilizar para multitud de tareas.
Pero la utilidad de cualquier herramienta va ligada a la capacidad para usarla. Y una forma de aumentar tu capacidad es crear métodos para optimizar o automatizar algunas de tus tareas.
Para finalizar el artículo te voy a explicar cómo puedes hacer un análisis rápido de competencia, utilizando de forma creativa las diferentes funciones que te ofrece Scrapebox
- Hazte con una lista de tus palabras clave, o las de tu cliente, o utiliza el Keyword Scraper como ya te he explicado al principio.
- Recolecta sólo los primeros 10 resultados (primera página de Google) para cada Keyword.
- Utiliza el Addon “Scrapebox Backlink Checker” con tu API de Moz para obtener la cantidad de Backlinks de tu competencia.

- Haz lo mismo para recolectar el “PA/DA” como ya sabes, gracias al Addon “Page Authority»
- Igual con el Addon “Social Checker»
- Recolecta emails de contacto con el Addon «Whois Scraper»
- Recolecta los meta tags de todas esas páginas como te acabo de explicar.
- También el Alexa Rank como ya sabes.
- Exporta y consolida toda esa información en un archivo Excel…
Y ya puedes analizar a tu competencia teniendo en cuenta sus backlinks, meta tags, métricas de cada dominio…
Ahora échale un poco de imaginación y comienza a crear tus propios sistemas con Scrapebox 😉
Recursos Ninja para Scrapebox
Muchas gracias por haber llegado hasta aquí, has demostrado tener muchas ganas de aprender y mucha paciencia, felicidades 🙂
Si no conocías Scrapebox espero que esta guía te haya descubierto algunas de las posibilidades de esta herramienta y te anime a investigar por tu cuenta y probar formas creativas de utilizarla.
Para ayudarte en esta tarea he preparado una página de recursos en NinjaSEO donde podrás encontrar entre otras cosas:
- Una lista de blogs sin moderar («auto approve»)
- Una lista de footprints
- Una guía para encontrar proxies públicos
- Ideas para encontrar blogs “auto approve»
- Trucos para crear comentarios más efectivos
- Una guía para indexar Backlinks usando RSS
Pincha en la imagen de abajo o en este texto para acceder

¡Gracias de nuevo y nos vemos en los comentarios!

Joe que pedazo de artículo y de guía para Scrapebox, me la guardo pero ya en mis favoritos para sacarle más partido y poder escudriñarla más a fondo. Gracias por el esfuerzo.
Gracias a ti, sin lectores el esfuerzo no compensaría 🙂
Hola Dean
Me guardo el post en favoritos, tengo que leerlo con detenimiento de nuevo, me has dejado sudando ja.ja.
Conocía Scrapebox, pero desde luego no sabía que se pudieran hacer tantas cosas con esta herramienta, fantástica guía.
1 saludo.
Gracias Gilbert, me alegro que te haya gustado 🙂
La verdad es que todavía se pueden hacer más cosas con Scrapebox, y otras formas muy creativas de utilizarla la herramienta además de las que he puesto en la guía.
Para mi lo más interesante de SB es precisamente lo que no le gusta a alguna gente, el que no sea una herramienta de «darle a start y listo», sino que tienes que pensar un poco y eso te ayuda a desarrollar tu comprensión sobre muchos aspectos del SEO y a crear y probar tus propios sistemas.
Saludos,
Javier
Buenas Gilbert,
Aquí la obra maestra es cosa del amigo Javier, yo le di temática y el creo el monstruo.. 😉
Creo que es una mega guía para guardarse a muy buen recaudo!
Un saludo tío
Juraito que iba a poner Hola Javier pero la inercia me hizo escribir Dean ja.ja
Perdona Javier (al cesar lo que es del cesar)
1 saludo
No hay problema Gilbert! Un abrazo.
Jajaja mi comentario en otro post es el ejemplo! Casi me emociono!! jaja
Tonterías aparte, increíble esta mega guía. Uso Scrapebox a menudo para ciertos proyectos y había muchas cosas que desconocía ¡eres todo un crack de este programa!
La verdad es que una gran mayoría piensa que este software solo sirve para blackhat pero la realidad es que si sabes usarlo bien puedes hacer whitehat perfectamente.
Un saludo y muchísimas gracias por compartir post así con nosotros ¡brutal!
Gracias JoseLab me alegra mucho saber que has encontrado algo de utilidad a pesar de ser usuario de Scrapebox 🙂
Es cierto que SB es bastante desconocido y que a veces hablas de él y enseguida te ponen un sombrero negro. Para ser sincero yo apenas lo uso ahora para BH puro, y sigo encontrándole mucha utilidad, y desde que sacaron el plugin Automator lo tengo siempre haciendo alguna cosilla.
Gracias por leer y comentar!
Exelente guia 🙂 ahora ya tengo la mente mas abierta sobre scrapebox
Gracias por leerla Yvan!
Enhorabuena por el pedazo de artículo que te has cascado Javier.
Es una guía muy completa y te has explicado muy bien, así que felicidades.
De primeras las conclusiones que saco es que scrapebox es una herramienta muy potente que hasta ahora no había querido conocer por su «mala fama», ahora he visto que es una navaja multiusos, Xenu, screaming frog, semrush… todo en uno ¿no?
Has explicado muchas funcionalidades pero con scrapebox también se puede generar contenido basándose en las keywords que selecciones, ¿es así o estoy confundido?
Un par de preguntas más, ¿hay alguna diferencia si utilizo scrape box en una máquina virtual? Y la última, dices que necesitas comprar proxies si quieres darle caña sin que bloqueen tu Ip pero que si lo utilizas con moderación no es necesario comprarlos, ¿podrías especificar un poco más la «zona segura» en la que nos podemos mover? Supongamos que me fuera a una biblioteca con mi portátil y me pusiera a scrapear a tope, entonces ¿bloquearían su Ip o son Ips de algún modo distintas que no son susceptible de bloqueo?
Te agradecería un montón si pudieras responder a todas mis dudas.
Un saludo y enhorabuena
Hola Eduard, muchas gracias por el comentario, muy bien planteado 😉
Scrapebox es una herramienta multi-uso, muy potente en buenas manos y sobre todo en manos a las que les guste experimentar, gracias a sus múltiples Addons y plugins de pago.
Eso sí, hay herramienta especializadas como por ejemplo las que mencionas, que pueden hacer la tarea más rápidamente y que son más sencillas de utilizar porque están exclusivamente diseñadas para eso. Xenu es un excelente ejemplo, no hay nada que funcione mejor para rastrear enlaces rotos.
Y sí, con Scrapebox puedes generar contenidos automáticamente… y publicarlos. Aunque para ello necesitas el plugin de pago «Article Scraper» con el que podrías recolectar contenidos de algunos directorios de artículos (Ezine por ejemplo), traducirlos automáticamente al Español, spinearlos y publicarlos. Pero ten en en cuenta que la calidad del artículo resultante deja bastante que desear y sólo podrías utilizarlo para un Tier3. Yo lo uso muy poco, y por eso no lo he puesto en el artículo, pero si hay interés igual hago un «reloaded» con los plugins de pago 🙂
Mi recomendación es que si te lo puedes permitir siempre utilices Scrapebox en un VPS. Además de la seguridad y de evitar bloqueos normalmente la velocidad que alcanzas es muy buena y cuando te montas un buen sistema de trabajo lo dejas ahí en marcha y va haciendo sus cositas, sin que te preocupes de nada… solamente que de vez en cuando Dropbox te avisa de que tienes un regalito en tu carpeta \dropbox\vps\SBtransfer\ 😉
Es complicado decirte hasta donde vas a necesitar proxies, porque depende del tipo de búsquedas. Las búsquedas con operadores (inurl, intitle, etc.), sobre todo si son sucesivas suelen quemarlos muy rápidamente. Y no es fácil encontrar proxies «Google passed» Pero si sabes lo que estás haciendo puedes funcionar con pocos proxies o sin ellos. Lo que sucede es que normalmente la gente se emociona y lanza una recolección a lo bestia y enseguida reciben un bloqueo y se frustran. O consiguen unos proxies que a los 10 minutos están muertos y comienzan a postear diciendo que SB no funciona. Por eso recomiendo comprar unos proxies baratos para ir jugando. O comenzar con pequeñas recolecciones sin proxies y testear lo que puedes hacer sin que te banee google.
¡Suerte!
Muchísimas gracias por tus respuestas Javier.
Por cierto, ¿qué te parece Market Samurai? Me interesa tu opinión al respecto y si crees que se puede comparar a ScraperBox o está muy lejos de su nivel.
¿Los ninjas se llevan bien con los samurais? 😉
Hola de nuevo Edu 🙂
Jaja, los Ninjas y los Samurai no se podían ni ver, los Samurai tenían un estricto código ético (digamos que eran WhiteHat) que los obligaba incluso a identificarse en las batallas y los Ninjas «hacían lo que hubiese que hacer» (digamos que eran BlackHat)
Bueno, coñas aparte, Market Samurai es una excelente herramienta, la he usado hasta sacarle brillo, y para determinadas cosas la sigo usando. Es muy recomendable, aunque como todo hay que saber usarla, pero no es ni de lejos tan complicada al principio como Scrapebox.
Pero Market Samurai y Scrapebox son dos bestias diferentes, como ya sabes SB es una herramienta que sirve para acelerar muchas de esas tareas fastidiosas que se hacían a mano (así nació) y gracias a su evolución y posteriores capacidades de automatización, se ha convertido en un ayudante valioso para muchos.
Market Samurai es una herramienta especializada para encontrar nichos, no tiene capacidades de LinkBuilding o de crear tus propios flujos de trabajo. Es decir, tiene menos posibilidades creativas pero lo que hace lo hace muy bien.
No hace ningún daño tener las dos, si te lo puedes permitir, pero recuerda que la acumulación de herramientas (y te lo dice uno que ha probado casi todo) no te hace mejor SEO ni es garantía de nada.
¡Suerte!
Jaja eres un pozo de sabiduría Javier, lo del código ético me ha encantado.
Gracias por darme tu opinión, me gusta probar un poco de todo antes de decidir qué elegir.
Saludos.
😀 eso te lo dan en la primera clase Shinobi 😉
¡Suerte!
OOOHH alabado seas!! 😉
Muy buena información y un pedazo de post te ha quedado!!!, la verdad es que artículos como estos no se encuentran a menudo por la web, te felicito y muchas gracias por toda la info.
Saludos!
Muchas gracias GrabielSEO 🙂
Pedazo post! Mega-larguísimo para poder explicarlo todo. Ninjaseo se lo ha currado mucho! Saludos
Gracias por el comentario!
Tenía combustible para rato, a mi particularmente me ha impresionado!! 🙂
Javier, impresionante post…
Me lo exporto a pdf porque es merecedor de tenerlo guardado muy cerca! Menuda currada te has pegado, se agradece enormemente.
Se conozca o no SB de antemano es una guía perfecta para ver las posibilidades que ofrece. Yo tampoco creo que deba asociarse con ningún tipo de sombrero.
¡Un saludo!
Muchas gracias Carlos, tu tampoco te quedas corto en tu blog 😉
Gracias por tan excelente guía.
Es una herramienta que no he utilizad y de la que tengo mala referencia por lo que se dice de ellas, pero creo que la utilizaré para «cosas buenas» que tiene un gran potencial.
Saludos!
Gracias a ti por leerla Edinson 😉
Sí, la mala fama de SB está justificada en cierto modo, pero hay muchos usos «white» para esta herramienta, y es una pena arrinconarla.
Saludos,
excelente pots bien explicado gracias
¡Gracias!
Ya decía yo que no era en vano lo de reservar todo el fin de semana para esta guía, es como un libro hecho post, gracias a Dean por invitarte y a ti por tanto tiempo dedicado a este artículo que es para una clase de maestría en ScrapeBox, yo apenas lo usaba para buscar los backlinks de la competencia, ahora veo que tengo mucho trabajo por hacer…
Saludos estimados!
Hola Johnny, muchas gracias por tu comentario y por tus ganas de seguir aprendiendo, si tienes dudas ya sabes 😉
Gracias por nada Johnny, gracias a vosotros por estar siempre al otro lado 🙂
Dean, muchísimas gracias por invitar a Javier a tu blog, este es uno de los mejores posts que he leído en mucho tiempo.
Sin duda, me ha convencido y me compraré scrape box, solo con el tiempo que me voy a ahorrar en el keyword research y en el análisis de la competencia, merece la pena.
Me surgen un par de dudas:
– Varios de los addons que comentas no valen para la última versión, ¿me recomiendas instalar la anterior o la beta?
– En el primer ejemplo de keyword research dices que no has usado proxies porque es una búsqueda pequeña… ¿cómo medimos eso? La verdad, me da yuyu que Google bloquee mi IP 🙂
Gracias de nuevos, cracks!
Me alegro de que te haya sido útil y te haya molado Val!! 😀
Es un contenido más que completo, la intención es que se haga un imprescindible para las personas que quieran usar esta herramienta
Un abrazo
Hola Val, Dean ha sido muy amable al ofrecerme su blog como escaparate 🙂
Sobre tus dudas, si las funciones que quieres utilizar todavía no tienen Addon desarrollado para SB 2 (está indicado en el artículo) entonces sí o sí tienes que utilizar la versión 1. La versión beta es mucho más potente y es la que utilizo más a menudo, pero es que yo tengo varias licencias de SB y utilizo tanto la 1 como la beta 1;-)
Para los que comienzan con SB yo recomiendo instalar y activar la versión 1 y más adelante pasarse a la 2, porque la misma licencia que compres sirve para las dos versiones, únicamente que no puedes usar la misma licencia a la vez. Tienes que desactivar una y activar la otra.
Como le comentaba más arriba a Eduard, es complicado cuantificar, pero para darte una pista piensa que a veces (si practicas SEO) haces varias búsquedas muy rápidas y en diferentes pestañas, y no te pasa nada. El problema viene cuando te lanzas a recolectar miles de resultados para cientos de keywords y no utilizas proxies, es normal que te bloqueen. Cuando yo hago búsquedas para una pocas keywords y sólo miro por ejemplo los primeros cien resultados desactivo mis proxies para que no se quemen, y no suelo tener problemas. Pero bueno, la medida te la dará la experiencia 🙂
¡Suerte!
Hola Javier,
La próxima vez que alguien me pregunte en qué consiste el contenido de calidad, lo voy a remitir a este artículo. 😉
La verdad es que conocía la mayoría de los usos que has descrito, pero las había visto en páginas americanas. Aunque personalmente, scrapebox me está dando algunos quebraderos de cabeza.
Ya que estoy, aprovecho para preguntar. Uso proxies privados (G passed), y aún así alguna vez le doy a harvester y Google me dice «not completed» ¿sabéis a qué puede ser debido?
Gran post, saludos.
Gracias Javier, es un piropo en toda regla 😉
Normalmente no se suele divulgar mucho este tipo de información «paso a paso, y cuando se hace se suele cobrar, aunque sea 10$ por un ebook o algo así, yo mismo lo he echo antes, en inglés… aunque he de reconocer que he simplificado mucho en este artículo para no terminar escribiendo un libro.
Si no puedes recolectar en Google con estos proxies y sí puedes hacerlo cuando los desactivas, el problema viene de ahí. Compruébalos en el Proxy Manager y mira a ver qué te dice, aunque en algunos casos que te de «Google Passed» no garantiza 100% que funcionen perfectamente, hay otros métodos para comprobarlo, pero ya estamos entrando en temas avanzados y se nos iría de las manos el artículo 🙂
Un abrazo,
Brutal es la mejor forma de describir este tutorial.
Imprimo y comparto.
Gracias Javier & Dean
Muchas gracias Estanislao, lo de imprimir creo que ha sido el mejor agradecimiento que he recibido en mucho tiempo 😉
Jajaja, que buena, muchas gracias Estanislao, ya de paso si te sacas una copia para mi te lo agradecería 🙂 jeje
Un artículo para imprimir ¡si señor!
Un abrazo
Muy bueno el artículo. Lo tenía comprado hace tiempo pero no lo utilizaba apenas. Creo que es el momento adecuado.
Pues a darle uso Sergio 😉
Gracias Dean por traer a Javier a tu blog pues no lo conocía, pero a partir de ahora te vigilaré de cerca… 😉
Enhorabuena por el articulazo Javier, yo soy más de videos que de paso a paso con imágenes. Sé el curro que lleva hacer algo así, y se agradece.
Un abrazo!
Muchas gracias por el comentario Omar, ya te conocía «de oídas» pero voy a fijarme más 😉
Yo hago la dos cosas, y la verdad hacer un vídeo también me cuesta lo suyo, termino yéndome por las ramas y tengo que cortar y empezar 10 veces 😀
Un abrazo,
Gran aportación. Me guardo este post.
Saludos
Gracias Carlos!
No puedo más que quitarme el sombrero (en este caso el negro xD) ante este pedazo de post de scrapebox.
La verdad que yo llevo tiempo utilizándolo sobre todo para conseguir y filtrar búsquedas de dominios caducados y es un soft que bien utilizado, tiene mil posibilidades.
Felicidades Javier por el post y a agradecer a Dean la calidad de todos sus contenidos!!
Gracias Wilfrido, tu agradecimiento tiene mucho valor ya siendo usuario de Scrapebox, y además en un tema tan interesante como la búsqueda de dominios caducados, más allá del TDNAM 😉
(P.S.: si no lo haces todavía prueba a integrar en tu workflow el plugin Automator)
Buenas Wilfredo!
Gracias a ti por pasarte y comentar de nuevo, se te echaba de menos por aquí 🙂
¡Por fin algo completo sobre esta herramienta!
Aunque la tengo que releer y apuntar muchas cosas, por fin leo algo detallado que resuelve muchas de las dudas que tengo.
Gracias por este fantástico post.
Gracias Jesús, si tienes alguna duda que se pueda resolver en un comentario, aquí estamos 😉
Hola Javier, solo una cosa. Tengo la versión 1.16 y por más que intento actualizar no me sale nada de la versión 2. Cómo se consigue? En la web oficial tampoco veo nada.
Hola Cidrex!
No se puede actualizar a la beta 2 desde Scrapebox, hay que descargar la beta desde http://www.scrapebox.com/v2-beta. Pero ten en cuenta que para usar la beta necesitas una licencia, y si sólo tienes una no podrás usar las dos versiones a la vez.
Si no tienes claro el tema de las licencias y cómo funcionan en SB por favor pregunta antes de hacer nada para no tener problemas, porque sólo puedes hacer un cambio de licencia al mes!
Saludos,
Puffff…Antes de nada E-N-H-O-R-A-B-U-E-N-A por esta mega-guía.
Tengo Scrapebox desde hace un tiempo y me esta dando «el flato» de no haberlo utilizado tan convenientemente como nos has contado Javier.
Me has dado trabajo de aprendizaje para un par de tardes por lo menos… Magnífico tutorial.
Gracias Pilladoxlared, una de las razones por las que me animé a compartir esta guía es porque sé que hay bastante gente que tiene licencias de SB pero apenas le da uso.
¡Suerte!
Hola
Lo único malo fue el titulo, por que debía ser HIPERMEGAULTRATUTORIAL DE SCRAPEBOX… jejejejeje
Lo único que les puedo decir es muchas gracias por semejante tutorial, directo a favoritos y como dice el compañero Estanislao Berruezo, imprimirlo.
Saludos desde Colombia
😀 Bueno, tu propuesta de título mola bastante, pero igual no es lomásmejor para el SEO 😉
Imprimid amigos, pero en dos caras, eh? hay que economizar papel!
Acabo de preguntar como puedo probar Scrapebox 2.0 teniendo la versión actual 1.16 y me borrais el comentario? Qué tipo de broma es esta? Soy suscriptor del blog y borrais una pregunta normal y corriente?
En fin me parece fatal
Cidrex, nadie te ha borrado nada! tu comentario estaba pendiente de moderación :O
De nuevo otros postazo como una casa de Javier… y digo «de nuevo» con conocimiento de causa!! jeje.
He estado pegándome con Scrapebox muchas veces pero al final, por problemas de falta de tiempo, no he terminado de sacarle el jugo que debería. Eso sí, después de este artículo no me queda otra que ponerme a ello a tope y quitar el polvo a la licencia adquirida hace un tiempo.
Me lo descargaré en pdf, lo imprimiré para ponerlo en el cabecero de la cama, y me guardaré en feedly el artículo por si falla lo anterior 😉
Un abrazo y buen fin de semana a todos!
Muchas gracias JaviEN, eres un tío genial y ya sabes que cuentas con mi ayuda si la necesitas!
Te has ganado un tuit 😀 A vuelo de pájaro veo que es bastante completo. Ha quedado guardado en favoritos para leerlo y practicarlo con mas calma. Gracias por tomarte el trabajo.
Muchas gracias Julián!
Genia aporte! Ya había leido algunas guías basicas, pero esta es la raja! A ahorrar para comprarlo!
Saludos
Gracias Luis!
He visto guías de «Scrape» gratuitas y en cursos online de pago y posiblemente esto está dentro de lo +completo q he visto con diferencia,
enhorabuena y gracias x vuestras aportaciones ! 🙂
Gracias por el comentario Javier!
Impresionante Javier, lo tengo medio leído, pero en casa lo pienso leer completamente (estoy en el curro :0), es muy bueno y completo.
Yo me estoy iniciando en todo este mundo de los blog y voy siguiendo varios blogs como este. Pero cometí un error muy grande, no se de que va mi propio blog, quise hacer un mix de varias cosas y ahora no se como catalogarlo. Pero bueno, me sirve de iniciación y de experiencia. A ver si juntando ideas de varios sitios y herramientas como la que nos presentas, puedo aunar todos los conocimientos y empezar de nuevo con algo decente.
Tengo una idea que no esta nada explotada, esta a nivel 0. Por mi trabajo, en el cual paso viajando por el mundo prácticamente 7 meses al año, existe un negocio en el que a día de hoy su representación en la red tanto en información como en blog esta prácticamente nula.
Un saludo y muchas gracias por contribuir cono todo el mundo y realizar esas pedazo de entradas dando a conocer una herramienta tan potente.
Gracias.
Hola Javier! (pero bueno, Javier debe ser el nombre más común en Internet!)
Gracias por el comentario, sin duda en esta web puedes aprender un montón porque está llena de buenos consejos y contenido de calidad.
El no saber «de qué va» una web o no saber comunicarlo a Google es una de las cosas más comunes, sobre todo cuando empiezas, por eso yo suelo recomendar comenzar con un nicho muy concreto y definido aunque el objetivo de la web a largo plazo sea más ambicioso. Pero bueno, de esto no va el artículo 🙂
Un abrazo,
Madre mía, Dean, vaya invitado te has buscado!
Lo de buen o mal SEO hay que analizarlo, como un dominio expirado, pero lo que no necesita mucho análisis es que Javier es un editor del copón.
Gran contenido, al detalle y muy muy claro.
Muchísimas gracias a los dos por un contenido genial!!
😀 Muchas gracias FranGarcia!
Está claro que en cualquier herramienta la mano que la maneja es la que decide cómo usarla, pero aún así hay que tener cuidado (y espero haberlo podido trasmitir en la guía) con algunas como es el caso de SB.
Por poner un ejemplo, un poco traído de los pelos: es complicado que alguien la fastidie mucho después de leer una guía de ahrefs y fácil que lo haga con una de SB. Las dos son herramientas, pero es mucho más peligrosa que la otra en manos no experimentadas.
Un abrazo,
Madre del amor hermoso…¡tengo los ojos más secos que la mojama!
GRACIAS por este pedazo de artículo. Voy directa a quemar la Espasa del salón y colocar esta auténtica enciclopedia del saber.
Saludos
😀 Gracias Marta!
Menudo postazo Javier. Enhorabuena..!!!
Dean ya me dirás como consigues invitados a tu blog de este nivel 😉
Un saludo
Gracias a ti por leerlo Andrés!
Dean es un estupendo anfitrión 😉
Hola Javier!!
Tremendo el artículo, por fin información de calidad acerca de esta fantástica herramienta!
Una duda, ¿Se podría utilizar para extraer información sobre los datos de una web en cuestión? Por ejemplo, imagina una web de hoteles, con su teléfono de contacto y correo electrónico de cada uno de los miles de hoteles que se anuncian. ¿Se podría usar scrapebox para sacar esta información y guardarla en un csv?
Muchas gracias!
Hola Rober, muchas gracias 🙂
Con SB podrías extraer los emails, con mayor o menor dificultad dependiendo del tipo de páginas, pero no es una herramienta con capacidades avanzadas de «data mining», para extraer otro tipo de información necesitarías una herramienta más especializada.
Saludos,
Ok, muchas gracias por la respuesta!
Alguna herramienta de data mining que recomiendes?
Muchas gracias!
Un saludo!
Hola de nuevo 🙂
No te puedo recomendar nada específico, ya que si se trata de scrapear páginas sencillas o poca cantidad lo hago con una extensión del navegador o descargo código y luego regex con algún editor… y si es complicado pero merece la pena por el volumen de trabajo que supondría y hay dinero para ganar, entonces un freelance para que construya una herramienta sencilla específica para esa web o webs.
Me perdonarás que no entre en detalle, no es el propósito de este artículo 🙂
Muy buena guía te felicito, esta muy muy completa y explicada, es halgo que hace falta 😉 saludos!
Gracias Alejandro 🙂
Hola Javier
Esto me cayo como anillo al dedo, casualmente me compre ese programa hoy porque había visto lo potente que es, pero realmente mi manejo es super básico y esto me ha venido ¡genial! Lo que no entendí muy bien es: ¿puedo trabajarlo sin proxy?
Te soy sincera, tengo un poco de miedo con una web que tengo muy consentida. He realizo uno que otro backlink y nada de tier, por lo que entendí es mejor hacer tier 1, 2 y 3 para aplicar este herramienta ¿no?
Wow trato de escribir pero mi cerebro no deja me pensar y no ordeno todas mis preguntas jajaja 😉
¿Este tipo de herramienta se recomienda aplicar para que tipo de trabajo (micronichos, E-commerce, multinicho etc.)?
Apenas tenga más duda te las dejo por aquí
Gracias y un fuerte abrazo
Saludos
Hola Tatiana!
Sobre los proxies como he comentado más arriba puedes utilizar SB sin proxies para recolectar información siempre que el volumen de búsuqedas no sea muy elevado y/o continuo. Para casi todo lo demás (comentar, pagerank, etc.) vas a necesitar proxies.
No utilices SB para crear enlaces hacia tu web principal, la mejor forma de utilizar esta herramienta sin peligro es para indexar otros backlinks o para ayudar a páginas satélite, perfiles, etc.
Como digo en el artículo SB se puede utilizar para muchas tareas, es cuestión de utilizarla con un poco de imaginación.
Saludos,
Gran artículo. Había leído algún otro artículo sobre Scrapebox, pero ninguno tan extenso ni tan detallado como éste… Lo agrego a marcadores, que esto tiene miga!
Gracias por el esfuerzo!
Gracias a ti Intrastat 🙂
Javier!… Enhorabuena por el tutorial, perfecto para los que desconocemos la herramienta. Muchas, muchas gracias… te debo dos cervezas! Un saludo
Muchas gracias Pau, te perdono las cervezas, con un tweet me basta 😉
Wow, muy buen aporte. Muchas gracias, tengo meses con mi licencia de scrapebox y ya hera hora de que ponga en buen uso ese ware. Gracias
Pues al ataque Chris!
Un tutorial de la Ostia!
Ahora las preguntas de rigor.. :/
Estoy probando la beta 2 y he creado un custom engine para españo) Bueno lo de creado esta demás, lo he clonado, y en el nuevo he cambiado como menciona «en» a «es»
http://www.google.com/search?complete=0&hl=es&q={KEYWORD}&num=100&start={PAGENUM}&filter=0
Uso proxys privados, y la configuracion de conections esta por default. Al momento de hacer un Harvester no me trae resultados… El que si me trae resultados es el que viene por default
http://www.google.com/search?complete=0&hl=en&q={KEYWORD}&num=100&start={PAGENUM}&filter=0
Pero tarda una barbaridad! No les ha pasado eso?
Les hago el test a mis proxys y vuelan y todos son google passed ya que son privados(20)
Curioso es que si hago harvester a YTB, Bing, Yahoo todos traen resultados mas rápido… Que será u.u
Hola Luis, me alegro que te haya parecido interesante.
En principio no debería darte ningún problema si la cadena de búsqueda es correcta, prueba a copiar y pegar la cadena completa en tu navegador y sustituye {KEYWORD} por una palabra cualquiera y {PAGENUM} por 1 para ver que sucede. Si te funciona así debería funcionar también en SB.
Saludos,
Ya se arreglo!
No se que le paso, solo fue cuestión de abrirlo de nuevo..
De nuevo gracias por el excelente aporte.
Me alegro Luís!
Buenas, una cosa, lo pongo por aquí porque es de esto mismo, cuando pongo el comando con el es para España, no me pasa de 100 resultados en el harvester en cambio lo cambio a en y con normalidad, alguna idea de que es?
El post desde luego el mejor que hay en Español.
Dios mio menudo post , excelente gracias !!!
Muchas gracias a ti por leerlo 🙂
Muy bueno tio! Muchas gracias, ahora me lo pensare a esto de scrapebox, se ve bien, y es un error que la mayoria de la gente piense que es solo para hacer black hat 😉
Gracias Manolo, me alegro que te haya sido útil 🙂
La verdad usted lo a dicho todo el que no aprende con este Tutorial no aprende con nada, lo pondre en el Top Seo, muchas felicidades y gracias por este excelente aporte, no puedo decir mucho, te llevaste todos los elogios, BENDICIONES
Muchas gracias Jose, nuestro objetivo con este artículo era que fuese útil 🙂
Hola Javier, enhorabuena, me ha parecido impresionante el tutorial.
Te seguiré en tu blog…
Tengo una duda, hasta que punto es necesario un VPS, utilizando proxies privadas.
Gracias
Hola, Alex, gracias por leértelo 😉
Yo te diría que si eres un usuario «normal» con proxies privados tendrás suficiente. Yo utilizo un VPS por dos motivos
El primero porque no me gusta «hacer ciertas cosas» desde mi propio ordenador, con mi proveedor y mi IP. Ya sé que aún así se puede saber «quien soy», pero (y llámame antiguo) soy más de la vieja escuela y tengo mis manías…
Y en segundo lugar porque el VPS está siempre en marcha, sé que está trabajando para mi mientras yo hago otras cosas, y corre más o menos en piloto automático. Ademas en mi VPS no sólo tengo SB sino más herramientas funcionando constantemente…
Saludos,
Javier, excelente!!!
Una pregunta, please:
¿Qué otras herramientas pones a trabajar en el VPS para gestiones SEO?
Hola sería posible utilizar Scrapebox para encontrar contenido desindexado sobre temáticas concretas en blogs?
Hola Marcos, no lamentablemente Scrapebox no es una herramienta pensaba para esta tarea.
Hola javier, en primer lugar felicidades , pedazo de guia te has currado. Solo una cosa me interesa la opcion del addon social cheker para ver los contenidos mas compartidos de un blog por ejemplo para ver que tematica seguir para postear, pero se puede automatizar el buscar sitemaps de blogs , porque no me queda muy claro con conseguir por ejemplo de elblogsalmon.com, su siitemap y poder uitlizarlo con scrapebox. Ya que solo me da las opciones de introucirlo mediante txt o de la lista escrapeada.
Gracias y un salludo !!
Hola Eduardo, no he entendido bien lo que quieres conseguir, pero voy a intentar responder.
Puedes scrapear sitemaps con el addon «Sitemap Scraper» como digo en el artículo, simplemente incluye el sitio o sitios mediante una búsqueda de sitios, keywords, importando, copiando-pegando, etc… cualquiera de los métodos que soporta SB.
Saludos,
Hola javier, la verdad es qeu si lo llegas a entender .. perdon por expresarme tan mal., queria preguntar si puede utilizarse scrapebox, para averiguar todas las urls de una web, un blog a mas señas, y despues con el addon social checker saber cuales tienen mas señales sociales.
Gracias y de nuevo disculpas por el anterior comentario.
Porque con el sitemap cheker no me aparecen las urls, y en algunas webs no localizo el sitemap
Hola javier me autorespondo, he conseguido averiguar el sitemap a través del robots.txt, he descargado lasr urls a traves de sitemapchecker y luego las estoy pasando por el addon social. Espectacular !!
Graciasssss
Hola Eduardo, lo siento no había entendido bien el sentido de la pregunta 🙂
Para intentar encontrar (digo intentar porque todas todas a veces no es posible) yo utilizaría una combinación de métodos: «site:» para encontrar las páginas indexadas; «Sitemap» para las que tal vez no están indexadas pero que el dueño del sitio quiere informar, y «Link Extractor» en todos los reusltados anteriores (ajustado a enlaces internos) para intentar extraer todas las páginas que existen y que están enlazadas de alguna forma entre sí.
Como digo no todas las páginas se pueden extraer por diversos motivos, pero siguiendo el proceso de arriba puedes llegar a conseguir bastantes. De todas formas si lo que te interesa es conocer cuales de ellas tienen más señales sociales, con lo anterior tienes suficiente, pues las páginas que se comparten más suelen estar indexadas y fácilmente accesibles mediante «site:»
Suerte!
¡Gran aporte y muy currada esta guía! No hay mucha información en forma de guía detallada (desde cero) sobre este estupendo programa Scrapebox.
¡Felicidades por tu web y éxitos!
Saludos,
Fer
Gracias Fernando, me alegro que te haya gustado 🙂
Wow!!!! quede muy entusismado con este post, muy agradable y claro, que trabajo tan padre hiciste, me cambiaste la perspectiva
Muchas gracias José Luis 🙂
Javiern, tengo una pregunta, Veo que usas la version 2 para hacer las busquedas y la otra version para los plugg y demas cosas.
Mi pregunta es, es igual de eficas la version 1 para busquedas de Keywords y de URLs o si varia a la version 2?
Comento eso por que ando siguiendo tu Post y bueno es algo tedioso cambiar de version de la 1 a las 2 o viseversa, entonses, la 1 veo que tiene casi todo
Hola Jose Luis, en realidad yo ahora uso casi exclusivamente la versión 2, es mucho más rápida y (si tienes buenos proxies) aguanta lo que le eches.
En el artículo he mostrado la versión 1 para enseñar ciertas técnicas para las cuales se necesitaban plugins que todavía no estaban (algunos aún no están) disponibles para la versión 2.
Hola Javier que opinas de este uso de scrapebox para seo local
Supongo que ya lo sabras pero por si acaso comparto. Para seo local es muy importante estar en directorios locales además de logicamente otras cosas. Para averiguar donde se ha registrado la compentencia buscais en google quienes estan mejor posicionados a nivel local para vuestra key.
Copiais la dirección de contacto y la url quedando algo como esto
calle me la invento nº 26, madrid www quesitiomasguapo com
Introducimos este footprint en scrapebox para que nos saque todos los resultados de la siguiente forma
calle me la invento nº 26, madrid – site: www quesitiomasguapo com
El menos es para que quite logicamente los resultados propios de la web. Nos apareceran muchos resultados, callejero etc, pero tambien directorios donde nuestra competencia ha dejado su dirección y url, siendo algunos de ellos locales.
Que opinas ?
Hola Eduardo, para eso es precisamente para lo que es especialmente útil Scrapebox: para rastrear y filtrar información en internet.
Da igual el tipo de información de que se trate, ya sea para SEO local identificando un footprint y destripando la estrategia de tu competencia, o para encontrar sitios que han pasado más desapercibidos.
Por si acaso: recordad que la dirección que pongáis debe ser la que aparece en las búsquedas en Google (copiar y pegar y que sea sólo una línea) y que a veces un mismo negocio aparece con direcciones ligeramente diferentes debido a contracciones y cosas así.
Muchas gracias por la aportación!
Gracias por la respuesta !! Ufff, acabo de releer mi comentario y sorry , parece que te quiera enseñar yo algo. Gracias por todas tus aportaciones. Saludoss
Hola Eduardo, no hay motivo para disculparse, tu comentario es excelente y muy oportuno porque este punto no está tratado en el artículo.
Yo no lo sé todo sobre Scrapebox (y sobre nada), y aprendo (o lo intento) todos los días.
Gracias de nuevo y un abrazo 🙂
Hola Javier,
Me has convencido jejeje, lo he comprado del tiron…..y ya estoy probando cosillas, la verdad que siempre me llamo la atención esta herramienta, pero con este post.. no hay dudas LA NECESITO!!!!! muchas gracias por este aporte.
Hola Jose, muchas gracias a ti por leer el artículo ¡y sobre todo por ponerlo en práctica!
Un abrazo,
Impresionante… Lo he leído del tirón.
No había pensado usar ScrapeBox por su mala fama…
Prefiero el WhiteHat, pero veo que también para esto puede ser muy útil.
Gracias por tu artículo y te seguiré en ninjaseo
Hola Javier, también es comprado el scrapebox, apenas comienzo a utilizarlo, muy bueno tu mega manual, mi pregunta es si es buena estrategia utilizar el scrapebox para buscar sitios para comentar manualmente, si es una buena practica (no penalizable por google) hacerlo así. Gracias a ti y a Dean por este aporte.
Hola Javier, muchísimas gracias por la guía pero hay una cosa que no me encaja.
Entre los addons de scrapebox no me aparece el blog analyzer.
¿Puede ser de una version anterior o han cambiado el nombre?
Muy buen tutorial.
A mi tampoco me aparece el Blog Analyzer y creo que es fundamental. No aparece ni la versión 1 ni la 2.
Saludos!
Si que aparece, yo lo tengo, tengo la versión 1.16.4. Entiendo que habeis pulsado en show avaliable addons para descargarlo no ?
Y ahora la pregunta a Javier , es recomendable hacer las acutualizaciones menores que nos indica, ahora está la 1.16 .6 o no?, es por si no aparecen addons como a los otros users.
Gracias
Yo tengo la version v2 de Scrapebox y ahí ya no aparece el Blog Analyzer…
Hola a todos, lamento el retraso en contestar, cosas de las vacaciones 🙂
Efectivamente el Blog Analyzer ya no existe en la versión 2, y su funcionalidad ha sido asumida por el addon «Page Scanner», que puede analizar las plataformas más comunes y mucho más.
Saludos,
Hola de nuevo, no logro configurar el api de moz en el scrapebox, cual es la forma de colocar el api, puedes poner capturas.
Hola Yorffih, en la parte donde hablo del addon «Page Authority» tienes una captura de pantalla…
Saludos,
Hola Javier gran articulo que te has montado, gracias por tu tiempo.
Quería hacerte unas consultas:
1. Con el tema de buscadores es decir obtener búsquedas de yahoo:
Esos motores de búsqueda los puedo obtener luego de haber configurado «Harvester Engine Configuration» ?
Porque según veo, por defecto sale google.com, me imagino que si luego actualizo a yahoo.com, me cambia el buscador, sera así?
2. En la búsquedas de key automático. Como lo hiciste?, yo coloque 2, imaginando que luego de la primera búsqueda pasaría al lado izquierdo y comenzaría nueva búsqueda. Pero nada.
3.
Para el indexado, ese archivo es actualizable? lo digo para no estar descargando y directamente lo subo de la pc.
4.
Me a pasado que de una lista de 10 mil url, al analizar el pagerank solo 2 a 3 me muestran, los demás error o nulo. A que se debe si estoy utilizando los proxis passed de scrapebox?
5. Que tal el article builder?
6. Por lo que leí, no es 100% seguro tener google passed, yo acabo de encontrar 91 y lo que hago siempre es para cada uso, volver a comprobar esos proxis anteriores así voy eliminando los que ya quemaron, y me quedo con los que aun siguen vivitos y coleando 🙂
7. Leí que el «Blog Analyzer» ya no funciona para la V2 , cual es Addon su reemplazo?
Nota: para hacer el análisis de la competencia lo puedes hacer con screaming frog, aunque ya lo debes saber.
Hola, antes que nada muchas gracias por este manual… por que los videos que recomiendan al comprar la app no se le entiende nada y se ven borrosos :O..
Tengo una duda, estoy en la fase de buscar los primeros 20 resultados de URL de Google (2 primeras páginas) para cada una de las palabras clave, pero salirme las HARVEST KEYWORDS STATICS, en la columna TOTAL y GOOGLE me salen 0. Y ya probé con diferentes tipos de palabras clave y en todas me sale eso 🙁
Me puedes apoyar, ya que estoy empezando en esto del SEO (estudiando una maestría) y quiero poder empezar a aprender técnicas y me recomendaron mucho usar Scrapebox ya que actualmente no tengo el capital para pagar tantas herramientas para el SEO ya que soy novato
Te lo agradecería muchísisimo
Mismo problema, lo pudiste resolver?
Hola Juan Carlos / Luis, cuando sucede esto el motivo más frecuente es que Google ha bloqueado temporalmente vuestra IP por scrapear los resultados. La solución más sencillas es esperar un poco hasta que expire pase el baneo y scrapear menos Kws a la vez. O conseguir/comprar Proxies que pasen el test de Google…
¡Suerte!
Una guía completísima de scrapebox, gracias a Dean y a Javier por hacerla y compartirla. De todos estos productos es difícil encontrar buenas guías en castellano, ya que desgraciadamente casi todo está en inglés. Saludos.
Gracias Ninjas, comparto 😉
Tremenda herramienta y tan mala fama que tiene, la primera vez que oide de ella fue en el blog de chuiso y parecia algo muy tenebroso, pero esta herramienta seo te ahorraria horas de trabajo talvez dias.
Sobre el truco de buscar clientes, vi un seo que busca las paginas sin meta tags y manda un mensaje muy convencedor que por que devia usar sus servicios seo es una variente de truco que comentas sobre analitics y adsense.
Hola David,
Si utilizo proxies privados, ¿puedo realizar todas las recolecciones que quiera durante un mes? ¿O si realizo demasiadas búsquedas los proxies durarán menos de un mes?
Saludos y gracias!
Fantástico, vaya pedazo de turorial !, he realizado la compra! Hasta ahora he estado muy limitado con mis trabajos Seo. Si tengo dudas, que las tendré, espero que me puedas ayudar Javier! 😉
Gran articulo, tengo scrape desde hace mucho pero nunca termino de sacarle rendimiento, espero sacar un poco mas de provecho ahora con este magnifico tuto, aunque el mayor problema como todo el que lo usa sabrá son los proxys. Un saludo y enhorabuena por el pedazo de articulo.
Muy buen tutorial! yo también compraré scrapebox 😀
Por cierto los enlaces a recursos no funcionan: http://ninjaseo.es/academia/wp-content/uploads/2015/03/Auto_Approve_Scrapebox_List.txt.zip
Muchas gracias!
Hola Vinilos, gracias por avisar, los enlaces ya deberían estar operativos, visita la página de nuevo.
Saludos,
Muchas gracias, me ira de lujo tu post!!
Hola, Javier. La palabra» impresionante» se queda muy corta y me refiero no sólo a un magnífico tutorial para una magnífica herramienta, sino también a tu aporte personal creativo sobre el uso de la misma.
He estado leyendo y leyendo opiniones sobre herramientas para linkbuilding o para automatización de tareas, pero SB lo hace todo!!
Tu post me ha hecho cambiar de xip. Estaba obsesionado por la automatización para el linkbuilding, leyendo sobre GSA SER, Senuke, Ultimate Demon, etc…pero ahora veo que se me olvidaba lo más importante: la «recolección» (como dices tú) de datos para planificar el proyecto y SB es, creo, inigualable.
Creo que voy a tomar una decisión al respecto.
Te agradezco este gran trabajo tuyo y el gran enfoque didáctico que le das al post, pues de hecho, la herramienta, tal y como comentabas, también lo es.
Felicidades!
Un abrazo.
Muchas gracias a ti Marcel, desde luego la «recolección» o el estudio, la planificación o como quieras llamarlo es un aspecto muy importante y que muchas veces se pasa por alto o se desestima…
Saludos,
Hola,
Una consulta, si usara un scrapebox en un vps sería necesario utilizar proxys también? O ya no haría falta?
Saludos.
Hola Sergio, sí sería necesario igualmente 🙂
Saludos,
Uy parece que llegue tarde jaja
Justo que estoy viendo como hacer para posicionar mis dos blogs que estan lejos del top 10, a ver si esto me ayuda. Sigue vigente alguna promocion para comprarlo? O me aconsejas usar la version de prueba hasta que lo maneje un poco?
Gracias!
Hola Ezequiel, Scrapebox no dispone de ninguna versión de prueba, pero puedes conseguirlo con mejor precio siguiendo el enlace que hay hacia Scrapebox en mi página.
¡Suerte!
Muchas gracias por el pedazo artículo realizado me ha servido de mucho!
Acabo de comprar la herramienta, sabía que se podían hacer muchas tareas con ella, pero luego de leer tu artículo quedé anonadado! Las posibilidades son realmente infinitas!
Muchísimas gracias por dedicarle tiempo a cada tarea con los ejemplos, creo que es donde me quedó más claro el uso de cada función del programa.
Un abrazo!
Muy buena guia.
Habra que sacar tiempo para aplicar con detenimiento tantas estrategias.
Hola Javier, primero te felicito por esta genial guía,
y te hago una preguntilla, estoy por comprar Scrapebox pero tengo una duda, ¿es posible utilizar una VPN en lugar de proxies para utilizar Scrapebox?
En mi caso pienso que no lo utilizaría de manera taaan masiva, solo un poco, mitad white hat (solo para scrapear un poco) mitad black hat, jeje, ya que todavía no estoy muy familiarizado con el.
Un saludo y gracias desde ya
Hola, felicidades por el articulo la verdad que es una pasada, el mejor que hay en español.
Los recursos no se pueden ver, tienes varias 301 a una Url de tu blog que esta vacía, mientras lo solucionas me tome la libertad de usar la cache.
http://webcache.googleusercontent.com/search?q=cache:kNYwoVjs3rQJ:ninjaseo.es/recursos-gratis/scrapebox/+&cd=1&hl=es&ct=clnk&gl=es
Saludos!
Pedazo de Post, si lo hubiera visto antes, lo hubiese adquirido de esta página mas barato, voy dedicarle varias horas a leerme tu tutorial hasta conocer bien la herramienta, para cuando la pueda utilizar porque me da el mensaje «unable to conncect to scrapebox server», la licencia esta correcta y los test de servidor están en verde. Si sabéis alguna solución os la agradecería.
Hola Javier!
Un post MAGNÍFICO donde los haya. Realmente has hecho un trabajo sublime.
Me inicié en scrapebox con otro post tuyo creo recordar, pero cada vez que busco algo y releo este, me parece mejor y mejor. Lo has bordado.
Sólo queria que me dieras un consejo: Ya he llegado a «necesitar» un servicio de decapcha, ¿Cual me recomiendas? ¿Funcionan realmente? ¿Invertiré bien mis escasos recursos?
Espero tu respuesta,
Muchísimas gracias… y muchos éxitos!
Enorme tutorial, va directo a favoritos, ya son varias veces que lo consulto, tras realizar sobre todo busquedas, la clave segun entiendo son buenos y unicos footprints!!! Gracias por compartir esto Dean
culpa de mi amigo NINJASEO 😉
Excelente Post, tiene bastante tiempo y sigue completamente vigente, felicitaciones!!
Enhorabuena por la guía práctica.
Utilizar estas estrategias para la implementación hará toda la diferencia
Buenas,
Un gran tutorial. Scrapebox es la aplicación que más uso. Una compra bien amortizada.
La uso desde para cosas tan tontan como hacerle un trimp to root a los dominios como para scrapear dominios caducados o recolectar información desde footprints.
Para mi gusto es de las aplicaciones más necesarias para un SEO, junto con Ahrefs o Semrush para linkbuilding y estudio de la competencia.
Ultimamente, desde hace un mes o así, para usar Scrapebox hay que utilizar muchos proxys, y que sean de calidad, especialmente para scrapear contenidos en Google. Está baneando con mucha facilidad. Bing y Yahoo aún aguantan peor Google en cuanto le das un pelín fuerte te deja de dar resultados.
Estaría bien ampliar el post con más trucos y cosas que se pueden hacer con Scrapebox.
Un Saludo.
Gracias por tu post excelente herramienta.
Madre mía de estar redactando y compartir información muy valiosa. Los tutoriales de Scrapebox están en inglés y es una maravilla encontrarlo muy bien explicado en español. Un gran Saludo y abrazo desde México.
Creo que he leído esta guía de scrapebox por lo menos 10 veces -y créanme, no exagero-. Entro leo, hago pruebas, regreso, sigo leyendo, hago pruebas. He aprendido más con este tutorial que con un buen rato sumergida en los videos de scrapebox. Quizás porque lograron hacerlo tan sencillo que hasta yo podría entenderlo jajaja
Saludos y gracias por compartir este tipo de material!!
Merito de Javier de NinjaSEO : ) me alegro!!
Muy buen tutorial, y probablemente una de las mejores herramientas de SEO, pero tengo una duda: que ratio de proxies hay que tener para scrappear unos ciertos numeros de peticiones de busqueda? Es decir con 10 proxies de los que te busca ScrapeBox puedo scrappear sin problemas a 500 peticiones o más?
Saludos
Exelente tutorial amigo, hace 2 años compre la herramienta scrapebox a mitad de precio, trate de aprender a usar la herramienta pero por falta de tiempo (trabajo) no pude, hoy en dia dispongo del tiempo suficiente para aprender a usarla. Me gusto la forma en la que explicas. Te confiezo que para la unica cosa que ocupaba scrapebox era para buscar dominios con una keyword especifica. Ahora me monte un foro y me gustaria poder posicionarla. exelente página te felicito.
Hola Dean
Es bastante impresionante este artículo, me hace sentir que el SEO blackhat es un mundo completamente aparte
Sin embargo, mientras iba leyendo, me dì cuenta que Scrapebox es una herramienta que puede ayudarnos, y mucho, en nuestro trabajo SEO, que no necesariamente tiene que ser black hat
Saludos